
Artykuł jest fragmentem książki pt. „Gospodarka Cyfrowa. Jak nowe technologie zmieniają świat”. Wcześniej w portalu publikowaliśmy odcinki dotyczące technologii założycielskich czwartej rewolucji, a także nowych modeli biznesowych czy platform internetowych.
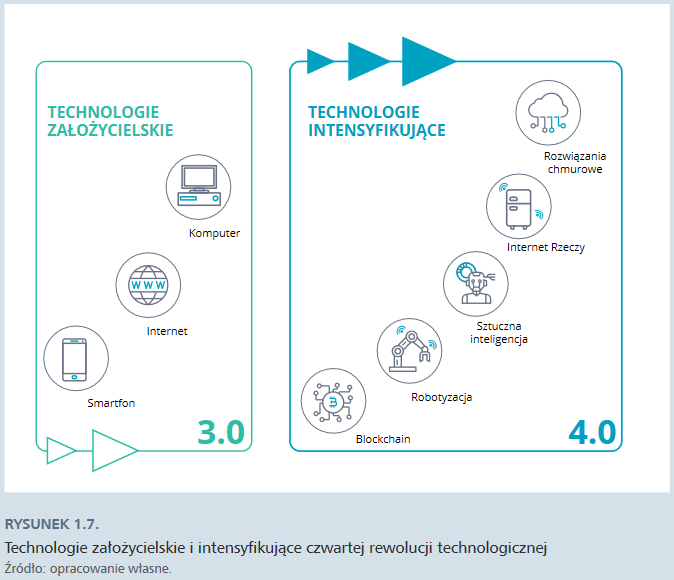
Komputer, internet i smartfon są uznawane za technologie szerokiego zastosowania (general purpose technology). Cechują się wszechobecnością, czyli zdolnością do rozprzestrzeniania się na wszystkie sektory gospodarki, ciągłym ulepszaniem i dynamizmem rozwoju oraz zdolnością do intensywnego pobudzania innowacyjności w wielu dziedzinach gospodarki i społeczeństwa. Stanowią też podstawę ekosystemu, na której błyskawicznie nadbudowują się kolejne wynalazki i innowacje. Niektóre z nich zaczynają być wdrażane przez firmy i używane przez zwykłych ludzi. Wykazują ogromny potencjał transformacyjny i z czasem same przekształcają się w technologie szerokiego zastosowania. Są to tzw. technologie intensyfikujące.
W warunkach przyspieszającej innowacji kombinatoryjnej zadanie mapowania trendów technologicznych i określania ich potencjału transformacyjnego nie należy do najłatwiejszych. Stąd też dużą popularnością w mediach cieszy się tzw. cykl Gartnera, zaproponowany w 1995 r. przez firmę doradczą Gartner. Według tej propozycji istnieje pięć faz dojrzewania technologii:
- Impuls innowacyjny (innovation trigger): w mediach zaczynają się pojawiać informacje na temat danej technologii, mimo że często sam produkt nie istnieje lub nie został jeszcze wprowadzony na rynek.
- Szczyt zawyżonych oczekiwań (peak of inflated expectations): fama medialna upowszechnia historię sukcesu i potencjalnych zastosowań innowacji (choć krążą też przykłady jej porażek). Nieliczne firmy decydują się na wdrożenie technologii, jednak większość zachowuje dystans.
- Dolina rozczarowania (trough of disillusionment): zainteresowanie nową technologią spada, gdy mnożą się przykłady nieudanych eksperymentów lub prób wdrożenia. Producenci znikają z rynku lub ulepszają produkty, dopasowując je do oczekiwań użytkowników.
- Stok oświecenia (slope of enlightenment): pojawia się coraz więcej przykładów efektywnego wykorzystania technologii w firmach, producenci wprowadzają na rynek produkty drugiej i trzeciej generacji, kolejne firmy decydują się na pilotażowe wdrożenie nowej technologii, choć te bardziej konserwatywne nadal trzymają się na dystans.
- Płaskowyż produktywności (plateau of productivity): wiele firm wdraża technologię, która znajduje rynkowe zastosowanie i staje się opłacalna.
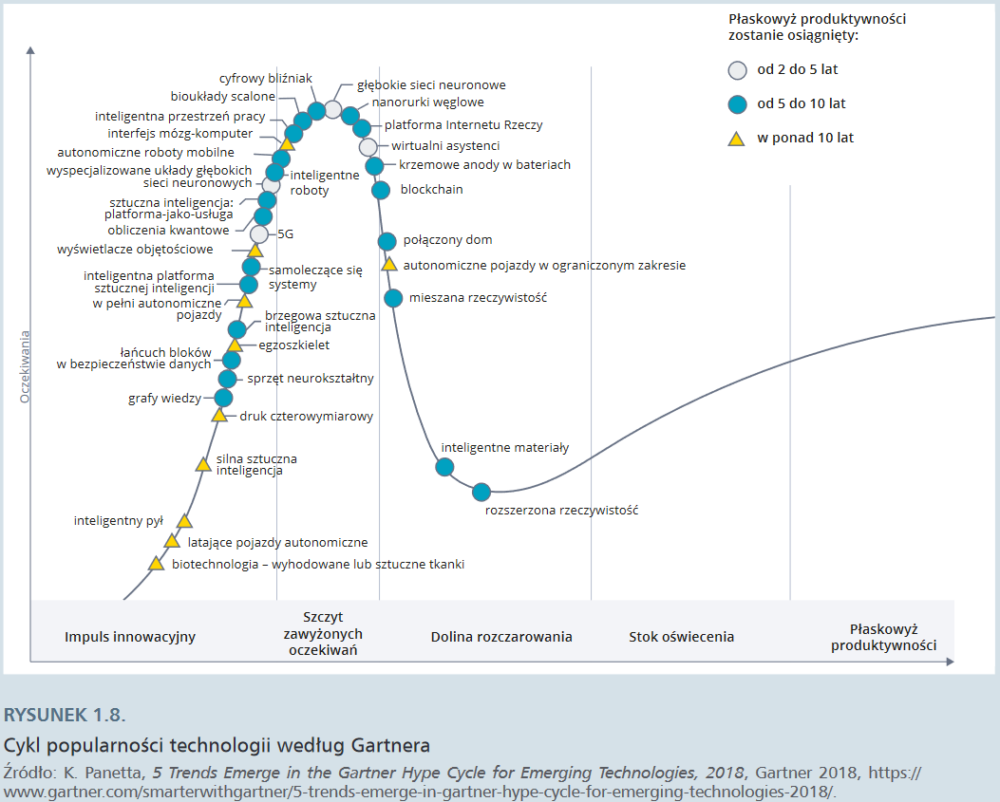
W 1998 roku na „płaskowyżu produktywności” lokowały się systemy rozpoznawania mowy (tworzące podstawy współczesnych Siri i Alexy) oraz „systemy oparte na wiedzy”, natomiast w 2008 – aplikacje oparte na lokalizacji użytkownika i podstawowe usługi w sieci.
Podobny wysiłek identyfikacji najważniejszych nowych technologii podejmują inne firmy konsultingowe, takie jak McKinsey czy Deloitte. W 2013 roku w raporcie Disruptive technologies: Advances that will transform life, business, and the global economy eksperci McKinseya wyodrębnili 12 technologii o największym potencjale zakłócającym (disruptive) dotychczasowe funkcjonowanie gospodarki i społeczeństwa. Na pierwszych pięciu miejscach uplasowały się: mobilny internet, automatyzacja pracy umysłowej, internet rzeczy, przetwarzanie danych w chmurze (cloud technology), zaawansowana robotyka i pojazdy autonomiczne. Postęp w rozwoju technologii zajmujących dalsze miejsca na liście – genomika drugiej generacji, technologie magazynowania energii, druk 3D, zaawansowane materiały, zaawansowane technologie wydobywania ropy naftowej i gazu oraz technologie energii odnawialnej – również w coraz większej mierze zależy od nowatorskich aplikacji ICT.
Ranking McKinseya opiera się na dość swobodnych szacunkach dotyczących skali oddziaływania na grupy społeczne, zasoby i produkty oraz potencjału generowania wartości ekonomicznej (w tym wpływu na wzrost gospodarczy i produktywność). Z kolei metodologia zaproponowana przez ekspertów Gartnera zasadniczo wychodzi od „konsensualnej oceny popularności i dojrzałości danej technologii” dokonywanej przez ekspertów firmy. Analitycy firmy posiłkują się „adekwatnymi sygnałami z rynku i przybliżonymi wskaźnikami w celu ustalenia poziomu oczekiwań. Część wkładu ma charakter ilościowy, jednak ogólnie rzecz biorąc, jest to ustrukturyzowane, jakościowe narzędzie badawcze”. Stąd też narzędzie to ma raczej charakter poglądowy.
Do kwestii identyfikowania technologii o największym potencjale transformacyjnym można podejść w bardziej metodyczny sposób. W ramach projektu Next Generation Internet Engineroom badacze z DELab UW – Maciej Wilamowski, Kristóf Gyódi, Michał Paliński, Łukasz Nawaro – przeanalizowali metodami analityki big bata i webscrapingu 140 tysięcy artykułów w pismach branżowych i 800 tysięcy w pismach naukowych. Na tej podstawie wyodrębnili technologie, które amerykańscy i europejscy eksperci i akademicy najczęściej wskazywali jako zyskujące na znaczeniu. W 2018 roku najczęściej pojawiały się pojęcia wiążące się z dwiema grupami innowacji: systemami rozproszonymi (w tym kryptowalutami oraz blockchainem) oraz sztuczną inteligencją (w tym również robotami oraz wirtualną rzeczywistością). Kolejne pozycje pod względem częstotliwości pojawiania się w tekstach zajmują sieci 5G, pojazdy autonomiczne, kwantowe przetwarzanie informacji, internet rzeczy oraz rozwiązania chmurowe.
Badacze DELab wyszli z założenia, że na trendach znają się najlepiej ci, którzy sami je tworzą – a więc wyspecjalizowani w nowych technologiach dziennikarze oraz naukowcy. A ponieważ pojęcie trendu jest de facto pojęciem z zakresu statystyki – trzeba zbadać, jak często i w jakich kontekstach pisze się o nowych zjawiskach. Tę metodologię dr Maciej Wilamowski, kierujący pracami polskiego zespołu Engineroom, opisuje jako połączenie wiedzy eksperckiej i narzędzi typu Google Trends, czyli po prostu analizę statystyczną dużych zbiorów danych. Najpierw jednak te dane należało zebrać. Napisane w tym celu programy sieciowe, tzw. scrapery, przez ponad trzy lata pobierały teksty z największych serwisów technologicznych, zarówno tych popularyzatorskich (jak Wired, Gizmodo, TechForge lub Guardian Tech, Reuters), jak i naukowych (np. arXiv, SSRN). W ten sposób powstała baza złożona ze 140 tys. artykułów opublikowanych w mass mediach oraz 800 tys. z portali specjalistycznych. Ten ogromny zbiór danych, liczący kilkadziesiąt gigabajtów, należało następnie przesiać, tak by uzyskać grupę najczęściej pojawiających się terminów – tych ostatecznie wytypowano 167. Dalsza praca miała już charakter jakościowy – zebrane terminy można było pogrupować według rozmaitych kryteriów, np. łącząc w 23 większe podgrupy tematyczne: AI, kryptowaluty, 5G, cyberbezpieczeństwo. Wyniki grupowania można obejrzeć na interaktywnym wykresie: https://ngi.delabapps.eu/ (tekst: Jakub Janiszewski).
W dalszej części tekstu omawiamy te technologie, które wyżej wymienione analizy trendu zgodnie wskazują jako istotne: chmurę, sztuczną inteligencję, Internet Rzeczy i robotyzację wykorzystującą AI. Do tej listy dorzucamy również technologię blockchainową, choć obecnie trudno wyrokować co do jej faktycznej użyteczności.

Rozwiązania chmurowe
Przełomowe znaczenie dla upowszechniania się nowych zastosowań technologii cyfrowych miało zwiększenie mocy obliczeniowej systemów IT dzięki możliwości korzystania z zasobów komputacyjnych – serwerów, baz danych, oprogramowania, archiwizacji – które nie znajdowały się na lokalnym komputerze.
Pierwsze rozwiązania chmurowe, które pojawiły się pod koniec lat 90. XX w., pozwalały firmom korzystać z oprogramowania, które nie było zainstalowane na ich serwerach. Obecnie tego typu usługi są powszechnie dostępne również dla użytkowników indywidualnych: w 2018 roku, po sześciu latach funkcjonowania, liczba użytkowników usługi Google Drive przekroczyła miliard. Jednak największy udział w rynku usług chmurowych w minionym roku miała firma Amazon (Amazon Web Services) – wynosił 33% i był większy niż łączny udział jej trzech konkurentów: Microsoft, IBM i Google. Usługi chmurowe rozwijają również chińskie firmy technologiczne (Alibaba Cloud, Tencent). Sam rozwój chmury jako usługi stanowi kluczowy czynnik przyspieszający transformację cyfrową firm: pozwala na wykorzystanie potencjału nowych technologii bez konieczności ponoszenia kosztów inwestycji w sprzęt i infrastrukturę.
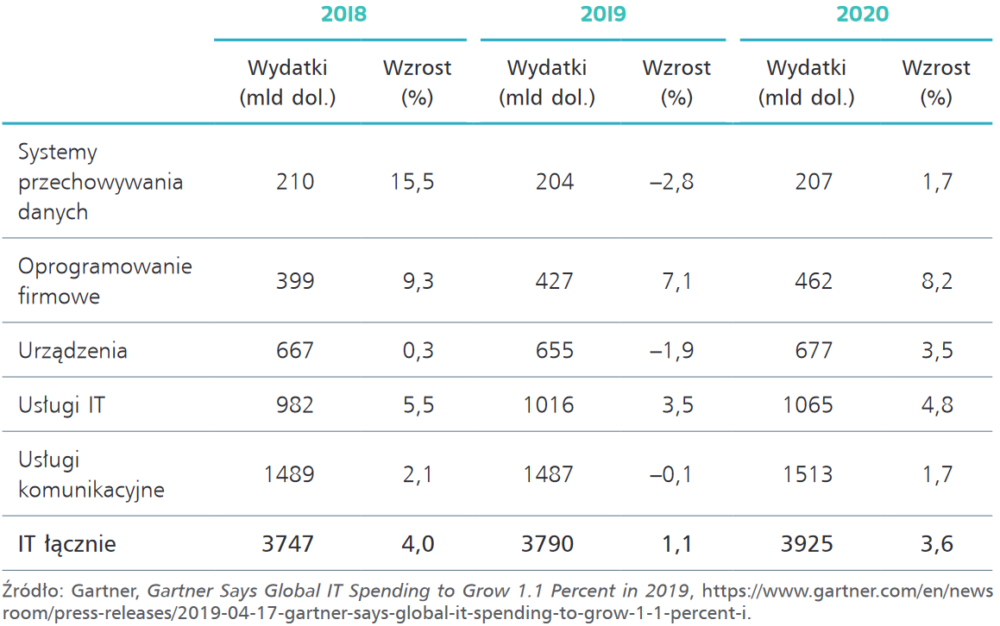
Podstawowe rodzaje usług chmurowych
| Rodzaj usługi: | Dostęp do: |
| Infrastruktura traktowana jako usługa (Infrastructure as a Service, IaaS) | przestrzeni dyskowej i mocy obliczeniowej |
| Platforma jako usługa (Platform as a Service, PaaS) | wachlarza aplikacji i oprogramowania |
| Software jako usługa (Software as a Service, SaaS) | konkretnego oprogramowania |
| Komunikacja jako usługa (Communications as a Service, CaaS) | rozwiązań komunikacyjnych |
| Platforma integracyjna jako usługa (Integration Platform as a Service, IPaaS) | infrastruktury integrującej programy i aplikacje działające w różnych środowiskach operacyjnych |
Przykładem oferty „software jako usługa” jest przeznaczony dla programistów serwis internetowy GitHub. Tworzenie kodu, programowanie – niezależnie od tego, czy mówimy o prostych projektach edukacyjnych, czy o zaawansowanych przedsięwzięciach komercyjnych – coraz częściej ma charakter zespołowy. W praktyce oznacza to wielokrotne zmiany tych samych fragmentów kodu, dokonywane na różnym etapie pracy przez różnych specjalistów. Do niedawna integracja tych zmian była procesem żmudnym, pracochłonnym i frustrującym. By zapanować nad chaosem, który nieuchronnie się wówczas pojawiał, opracowano tzw. repozytoria kodu, czyli narzędzia służące do integracji i synchronizacji danego projektu. Jednym z nich jest Git, czyli rozproszony system kontroli wersji służący do zarządzania historią zmian w kodzie. GitHub zaś to platforma działająca w oparciu o Git, na której programiści mogą przechowywać swoje projekty i bezpiecznie nad nimi pracować. Jak ujmuje to jedna z koderek na swoim blogu: „Git jest narzędziem, a GitHub usługą, gdzie możemy trzymać projekty korzystające z Gita”. O popularności GitHuba świadczy liczba przechowywanych projektów – w lutym 2018 r. było ich około 38 mln. W czerwcu tego samego roku serwis został kupiony przez Microsoft za cenę 7,5 mld dolarów.
Nadzieję na jeszcze szybsze i wydajniejsze przetwarzanie danych dają rozwiązania w zakresie rozproszonego przetwarzania w chmurze. Tradycyjne metody podejścia do ich analizy zakładają, że najpierw wszystkie dane musimy zapisać w centralnym punkcie, by następnie przystąpić do ich analizy. Takie założenie przy sporym wolumenie danych wpływa negatywnie na czas analiz. Efektywniejsze przetwarzanie danych umożliwia mgła obliczeniowa (fog computing) – wstępna analiza danych odbywa się już w miejscu ich powstania, zanim zostaną przesłane i przeanalizowane w systemie centralnym. Zapewnia to większą szybkość i wydajność analizy nawet przy łączności o niskiej jakości, co umożliwia funkcjonowanie inteligentnych urządzeń w ramach internetu rzeczy. W tym przypadku coraz większego znaczenia nabiera przetwarzanie brzegowe (edge computing), zachodzące na konkretnym urządzeniu (odciążenie chmury obliczeniowej, wykonujące za nią część obliczeń lokalnie).

Internet rzeczy
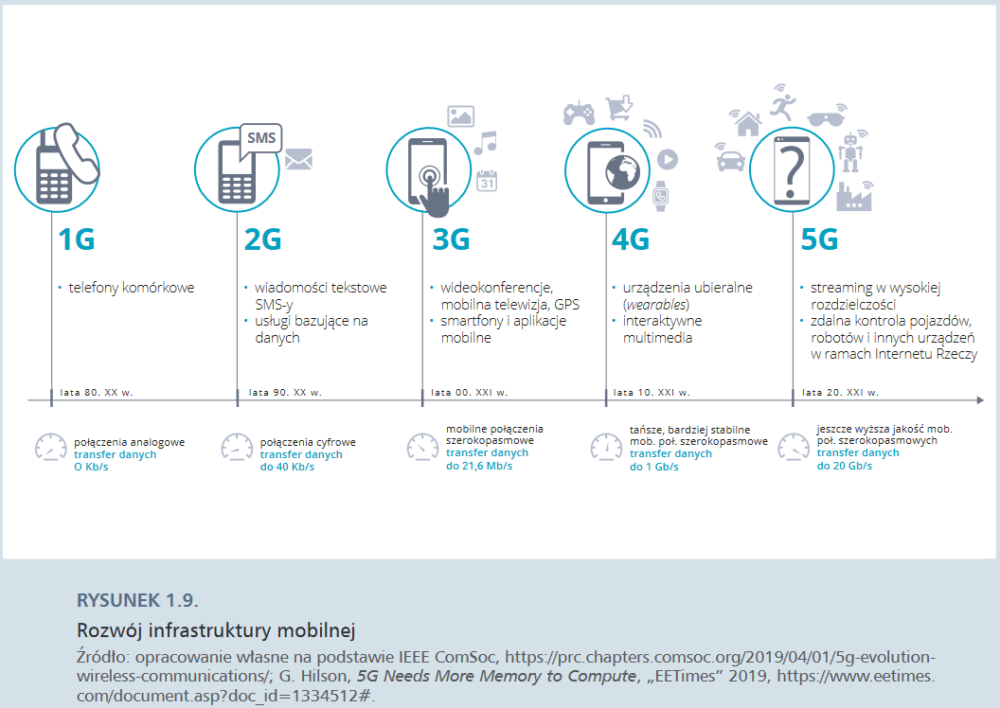
Kluczowym czynnikiem rozwoju chmury był szybszy internet. W 2019 roku w decydującą fazę weszło wdrażanie nowego standardu połączeń mobilnych – 5G. Zapewni on przesył danych o prędkości do 100 GB/s, co pozwoli zminimalizować opóźnienia i zużycie baterii (nawet o 90%), a przede wszystkim – umożliwi podłączenie znacznie większej liczby urządzeń. Dzięki 5G indywidualni użytkownicy będą mogli szybciej ściągać gry i oglądać filmy w lepszej jakości. Największe przyspieszenie nastąpi jednak w rozwoju tzw. internetu rzeczy. Dotychczasowy standard 4G umożliwiał podłączenie 110 tysięcy urządzeń na kilometr kwadratowy, standard 5G umożliwi podłączenie ponad miliona. Z perspektywy rozwoju autonomicznych pojazdów znaczenie ma również fakt, że sieć 5G zapewnia łączność obiektom poruszającym się z prędkością kilkuset kilometrów na godzinę z opóźnieniem transmisji nieprzekraczającym czterech milisekund.
W lutym 2018 r. Huawei zaprezentował pierwszy chipset przeznaczony dla nowego standardu – Balong 5G01. Maksymalna prędkość przesyłu danych miała w jego wypadku wynosić 2,3 Gb/s. To znacznie więcej niż w przypadku sieci 4G, ale wciąż o wiele mniej niż spodziewana maksymalna przepustowość rozwiązań 5G, szacowana na 20 Gb/s. Może się jednak okazać, że na osiągnięcie tego pułapu nie będziemy musieli długo czekać. Zaprezentowany w kwietniu 2018 roku Exynos Modem 5100, opracowany przez Samsunga, umożliwia przesył danych z prędkością 6 Gb/s, a więc pięć razy szybszą od urządzeń poprzedniej generacji i trzy razy szybszą od propozycji Huawei.

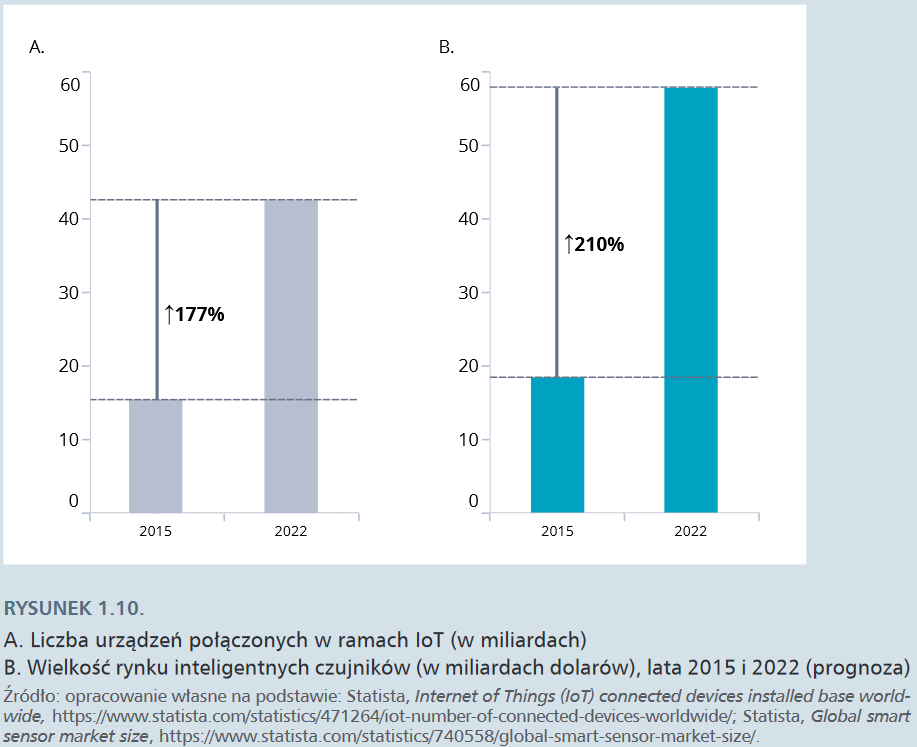
Internet rzeczy (internet of things, IoT) to sieć połączeń między przedmiotami fizycznymi wyposażonymi w czujniki (sensory), umożliwiająca przepływ danych między nimi. Przedmioty należące do sieci potrafią się cyfrowo identyfikować i komunikować z innymi urządzeniami. Niektórzy badacze mówią nawet o powstaniu „drugiej gospodarki”, w której przedmioty „rozmawiają ze sobą” poza naszą wiedzą. Rozwój IoT jest warunkowany nie tylko przepustowością sieci, ale również postępem w dziedzinie miniaturyzacji przejawiającym się powstaniem inteligentnych sensorów. Inteligentny sensor jest połączeniem czujnika z mikroprocesorem, jego integralną częścią jest wyspecjalizowany zespół obwodów elektrycznych (signal conditioning circuitry) pozwalający monitorować i kontrolować samego siebie i inne urządzenia. Inteligentny sensor nie tylko zbiera określone parametry otoczenia fizycznego, ale przede wszystkim wykorzystuje własne zasoby komputacyjne do ich analizy i przekazywania informacji w razie wykrycia specyficznej zmiany w otoczeniu. Rozpowszechnienie inteligentnych czujników stało się możliwe dzięki stabilnemu spadkowi ich ceny (z 1,3 dolara w 2004 r. do mniej niż 60 centów w 2014 r.). W 2006 roku na świecie funkcjonowały dwa miliardy inteligentnych czujników; w 2020 r. – nawet 200 miliardów.
Większość inteligentnych czujników jest obecnie wykorzystywana w przemyśle (są to np. czujniki ciśnienia, temperatury, podczerwieni czy zbliżeniowe). Na bieżąco monitorują pracę maszyn, co pozwala na wczesne zapobieganie awariom, są kluczowym czynnikiem automatyzacji transportu i dostaw, optymalizacji ruchu urządzeń i pojazdów w halach produkcyjnych i zarządzania stanem magazynu. Pomagają także kontrolować konsumpcję energii poprzez dopasowanie zużycia do potrzeb.
Rozwój IoT zmienia też styl życia ludzi. Inteligentne czujniki znajdują szerokie zastosowanie w wearables, czyli urządzeniach wbudowanych w ubrania czy rozmaite akcesoria, takie jak zegarki, bransoletki czy pierścionki. Są one wykorzystywane przede wszystkim do monitorowania funkcji fizycznych ciała, głównie przez zwolenników zdrowego stylu życia, ale też może znajdą szersze zastosowanie w służbie zdrowia. Czujniki wbudowane w specjalne bransoletki mogą mierzyć podstawowe parametry życiowe i alarmować system opieki zdrowotnej w razie wystąpienia nieprawidłowości. W 2021 r. liczba tego typu urządzeń ma przekroczyć 900 mln. Rozwój IoT jest też kluczowym czynnikiem rozwoju inteligentnych miast (smart cities) z inteligentnymi budynkami, mieszkaniami i transportem. Nasycanie otoczenia urządzeniami rejestrującymi wszelkie przejawy aktywności jednostek rodzi jednak wiele obaw związanych z bezpieczeństwem danych i ochroną prywatności użytkowników. Wyzwaniem dla budowy inteligentnego ekosystemu miejskiego jest też zbudowanie wysokiej interoperacyjności, czyli zdolności do efektywnej współpracy między sobą tworzących go urządzeń.
Sztuczna inteligencja
W sierpniu 1955 r. amerykański matematyk i informatyk John McCarthy wraz z grupą współpracowników złożył wniosek o finansowanie seminarium na temat „sztucznej inteligencji”:
Projekt przewiduje organizację dwumiesięcznego badania nad sztuczną inteligencją prowadzonego przez 10 badaczy latem 1956 r. w Dartmouth College. Badanie opiera się na założeniu, że każdy aspekt uczenia się lub inna cecha inteligencji może być w zasadzie tak precyzyjnie opisany, że będzie można zbudować maszynę, która zdoła je naśladować. Zostanie podjęta próba dowiedzenia się, jak sprawić, by maszyny używały języka, tworzyły abstrakcje i koncepcje, rozwiązywały problemy, które obecnie są domeną człowieka, i potrafiły się samodoskonalić. (…) wprawdzie szybkość i zasoby pamięci obecnych komputerów są zbyt ograniczone, by mogły one naśladować wiele z wyższych funkcji ludzkiego mózgu, ale główną przeszkodą nie jest ograniczony potencjał maszyn, lecz nasza nieumiejętność pisania programów, które w pełni wykorzystują to, czym dysponujemy.
To właśnie McCarthy zaproponował użycie pojęcia „sztuczna inteligencja” na określenie badań nad problemem „myślących maszyn”. Wydawało mu się najbardziej neutralne i godziło cybernetyków, teoretyków automatyzacji i badaczy zajmujących się złożonym przetwarzaniem informacji. Jednak palma pierwszeństwa w badaniach nad „myślącymi maszynami” należała do brytyjskiego matematyka Alana Turinga.
W 1951 r. Alan Turing napisał słynny artykuł Maszyneria licząca a inteligencja (Computing Machinery and Intelligence). Tekst zawdzięcza swoją sławę koncepcji „testu Turinga”, który miał posłużyć do sprawdzenia, czy dana maszyna jest w stanie myśleć. W rzeczywistości artykuł miał nieco inny cel, a i sam sposób opisu rodził wiele konfuzji. W potocznym ujęciu Turing miał proponować w sytuację, w której osoba przesłuchująca (człowiek) zadaje pytania dwóm istotom, których biologicznego statusu nie zna – jedna jest komputerem, druga człowiekiem. Jeśli przesłuchującemu nie uda się odróżnić, kto jest kim – maszyna zdaje test i należy ją uznać za inteligentną. Tymczasem to, co naprawdę napisał Turing, mocno odbiega od obiegowej wersji. W swoim tekście uczony starał się uciec od nieskończenie skomplikowanych dywagacji wokół znaczeń terminu „myślenie” i zamiast tego zaproponował trywialną metaforę sytuacyjną. „Tę nową postać problemu objaśnię, opisując pewną grę, którą nazwiemy «grą w udawanie». Biorą w niej udział trzy osoby: mężczyzna (A), kobieta (B) i przepytujący (C) – nieważne, jakiej płci. Przepytujący jest oddzielony od pozostałych dwojga uczestników. Jego zadaniem w grze jest ustalenie, które z nich jest mężczyzną, które kobietą”. Ta bardzo bliska grze w kalambury sytuacja miała w przystępny sposób wyjaśniać rozumienie inteligencji przez samego Turinga. Ale, jak twierdzą jego biografowie, matematyk wszystko poplątał do tego stopnia, że tylko bardzo uważna analiza tekstu pozwala odtworzyć jego rzeczywiste intencje. Turing pisał bowiem dalej: „Zapytajmy teraz: «Co będzie, jeśli rolę A w tej grze powierzymy maszynie?» Czy przepytujący będzie się mylił równie często, gdy gra przebiega w ten sposób, jak wtedy, gdy w grze biorą udział mężczyzna i kobieta?”. W efekcie wielu interpretatorów zaczęło sądzić, że test Turinga polega na odgadnięciu, że jeden z odpowiadających jest maszyną udającą mężczyznę, który udaje kobietę, co w istocie zakrawało na absurdalny żart. Tymczasem Turing, według dzisiejszych interpretatorów jego pracy, chciał jedynie w obrazowy sposób wykazać, że skuteczne udawanie inteligencji jest inteligencją, niezależnie od tego, w jaki sposób przebiega sam proces, który do owych przejawów prowadzi, i z czego zrobiona jest sama maszyna. Turing przewidywał – nietrafnie, jak się okazuje – że w roku 2000 komputery będą w stanie na tyle dobrze imitować człowieka, że w przypadku 70% pięciominutowych testów przesłuchujący nie będzie w stanie zidentyfikować maszyny. Jak dotąd najbliżej przejścia testu Turinga był Google Duplex AI Demo, który w maju 2018 r. na zaawansowanym poziomie poradził sobie z symulacją rozmowy telefonicznej między dwiema osobami.

Już w czasie założycielskiej konferencji w Dartmouth uczeni podzielili się na dwa przeciwstawne obozy w kwestii konstruowania sztucznej inteligencji: symboliczny i statystyczny. W pierwszym obozie znaleźli się ci badacze, którzy uważali, że sztuczną inteligencję można skonstruować, tworząc ścisły zbiór reguł, za którymi miała ona podążać w procesie rozwiązywania problemów. Spektakularnym sukcesem symbolistów stał się program „Logik”, wykorzystujący zasady logiki formalnej do automatycznego dowodzenia twierdzeń matematycznych. Jak piszą w swojej książce Machine, Platform, Crowd (2017) Erik Brynjolfsson i Andrew McAffee, program nie tylko udowodnił 38 twierdzeń umieszczonych w słynnej pracy Principia Mathematica, lecz również dla jednego z tych twierdzeń znalazł dowód bardziej elegancki niż ten, który zaproponowali jego autorzy. Symboliści stworzyli też program do gry w szachy i ogłosili, że udało się im stworzyć „myślącą maszynę”. Nic dziwnego, że lata 60. zdominował wielki optymizm co do możliwości stworzenia maszyny równie albo nawet bardziej inteligentnej od człowieka. Wiara w powodzenie projektów przekładała się na wysokie i niemal bezwarunkowe finansowanie pomysłów wielu uczestników konferencji w Dartmouth. Dopiero raport Lighthilla z 1973 r., poświęcony ewaluacji brytyjskiego sektora badań nad AI, ostudził oczekiwania. Publikacja w bardzo krytyczny sposób weryfikowała dotychczasowe osiągnięcia badaczy w tej sferze i dobitnie pokazywała rozdźwięk między szumnymi zapowiedziami a rzeczywistymi efektami zainwestowanych w AI środków. Maszyny nie nauczyły się rozpoznawać mowy, klasyfikować obrazów czy tłumaczyć z jednego języka na drugi.
Według często przytaczanej anegdoty o początkach tłumaczenia z wykorzystaniem maszyn badacze próbowali przetłumaczyć za pomocą programu zdanie z Ewangelii św. Mateusza „Duch jest wprawdzie ochoczy, ale ciało słabe” z angielskiego na rosyjski. W rezultacie otrzymali: „Wódka jest niezła, ale mięso się zepsuło”.
Raport doprowadził do ograniczenia badań nad sztuczną inteligencją w Wielkiej Brytanii do trzech ośrodków akademickich, jednocześnie dając początek kilkuletniemu okresowi tzw. zimy sztucznej inteligencji (AI winter).

Wiosna przyszła wraz z jaskółkami postępu technologicznego. Większa moc obliczeniowa komputerów i pojawienie się dużych zbiorów danych produkowanych przez użytkowników internetu sprawiły, że pole do popisu zyskali wreszcie zwolennicy drugiego obozu. Statystycy zakładali, że komputer „karmiony” dużymi zbiorami danych sam nauczy się wyłapywać trendy poprzez ciągłe powtarzanie, eksperymentowanie i informację zwrotną. Początkowe próby były niezbyt udane: pierwsza „ucząca się maszyna”, tzw. Perceptron zbudowany w 1958 r. przez Franka Rosenblatta, nie radziła sobie z podstawowymi klasyfikacjami. Zasada jej działania polegająca na próbie odwzorowania funkcjonowania ludzkiego mózgu, stanowiącego sieć neuronową, zainspirowała jednak kolejnych badaczy. Pod koniec lat 80. pojawiły się pomysły budowania bardziej złożonych sieci neuronowych, opartych na tzw. wstecznej propagacji, gdzie informacja mogła przemieszczać się w obydwu kierunkach w ramach sieci. Pomysł ten mógł zostać w pełni sprawdzony wraz z pojawieniem się ogromnych i przystępnych cenowo zasobów komputacyjnych związanych z przetwarzaniem w chmurze, które umożliwiły budowanie wielowarstwowych sieci neuronowych. Jak zauważył komentator MIT Technology Review, w rezultacie „sztuczna inteligencja wreszcie zaczyna być inteligentna” (artificial intelligence is finally getting smart).

Obecnie większość badań nad sztuczną inteligencją dotyczy uczenia maszynowego (machine learning) i głębokiego uczenia (deep learning). Uczenie maszynowe to algorytmy, które analizują dane, uczą się z nich i na tej podstawie podejmują decyzje. Głębokie uczenie to zasadniczo uczenie maszynowe o bardziej złożonych funkcjach, działające na zasadzie wielowarstwowych sztucznych sieci neuronowych, nieco przypominających strukturę mózgu człowieka. Uczenie maszynowe i głębokie mogą mieć charakter nadzorowany (supervised), nienadzorowany (unsupervised) i wzmocniony (reinforced). W pierwszym przypadku program dostaje dane, które są już oznaczone etykietami przez człowieka, co wyznacza kierunek uczenia się, w drugim – program sam decyduje, które dane są istotne. W przypadku uczenia wzmocnionego sztuczna inteligencja testuje rozmaite rozwiązania i wybiera te najlepsze dla osiągnięcia wyznaczonego celu. W rezultacie w niektórych obszarach maszyny zaczynają wyprzedzać możliwości intelektualne ludzi.
W 2016 r. program AlphaGo, zbudowany przez oddział Google DeepMind, pokonał koreańskiego mistrza go, starożytnej chińskiej gry, znacznie bardziej złożonej niż szachy. Sztuczna inteligencja samodzielnie nauczyła się grać na mistrzowskim poziomie, rozgrywając sama ze sobą milion rund. AlphaGo Zero – kolejna wersja programu – jest aktualnie najlepszym graczem w go na świecie. W następnym kroku Google rozszerzył oprogramowanie AlphaGo o inne gry. Mistrzowski poziom w szachach program osiągnął w ciągu doby. Wprawdzie już 1997 r. superkomputer Deep Blue IBM wygrał rywalizację z ówczesnym mistrzem świata Garrym Kasparovem, jednak w przypadku nowego programu czas rozgrywek, zużycie danych, mocy obliczeniowej i ludzkiej interwencji ograniczone został do minimum, a wydajność i wyniki osiągnęły najwyższy poziom. AI dobrze radzi sobie z grami o doskonałej informacji, jednak w przypadku gier o większej liczbie niewiadomych i losowym charakterze napotyka trudności. W 2016 r. grupa badaczy z University of Alberta w Kanadzie, Uniwersytetu Karola w Pradze i Politechniki Czeskiej stworzyła program DeepStack, który przeprowadził ponad 10 mln losowo wygenerowanych rozgrywek w pokera (w jego odmianie zwanej Texas Holdem). Aby odtworzyć przebieg ludzkiego rozumowania, program nie brał pod uwagę całego przebiegu gry, lecz skupiał się na dwóch krokach naprzód. Inny program – Libratus, stworzony przez badaczy z Carnegie Mellon University w 2017 r. – pokonał po kolei czterech najlepszych profesjonalnych graczy w turnieju w Rivers Cassino w Pittsburghu, w którym wzięło udział 60 tys. graczy. Sukcesy te pokazały jednak nie tylko możliwości sztucznej inteligencji, ale i jej ograniczenia – programy nadal działają w ramach baz danych, na których zostały wytrenowane, i nie radzą sobie z sytuacjami nietypowymi lub chaotycznymi.
Pionierami intensywnych inwestycji w rozwój uczenia maszynowego i głębokiego są korporacje technologiczne, takie jak Amazon, Google czy Facebook, dysponujące niewyobrażalną ilością danych wytwarzanych przez ich klientów.
AI staje się „mądrzejsza” i uczy się szybciej, gdy ma dostęp do większej ilości danych. Codziennie paliwo, napędzające uczenie maszynowe, jest wytwarzane przez przedsiębiorstwa. Wydobywa się je z rafinerii danych, takich jak Amazon Redshift, pozyskuje dzięki potędze „tłumu” za pośrednictwem Mechanical Turk oraz dynamicznie wykopuje dzięki Kinesis Streams. Ilość danych do analizy – z dotąd nieuwzględnianych źródeł, miejsc, obiektów i wydarzeń – rośnie niewyobrażalnie wraz z upowszechnianiem się technologii sensorów i nadejściem internetu rzeczy.
Na swojej stronie Amazon podkreśla, że „bez uczenia maszynowego amazon.com nie mógłby rozwijać biznesu, poprawiać doświadczenia konsumenckiego i dopasowania (customer experience and selection) oraz optymalizować szybkości i jakości logistyki”. Google deklaruje, że uczenie maszynowe i głębokie są dla firmy priorytetem, ponieważ pozwalają tworzyć „coraz inteligentniejszą, coraz bardziej użyteczną technologię, będącą pomocą dla jak największej liczby ludzi”. Na czele Facebook AI Research stoi Yann LeCunn, jeden z ojców uczenia głębokiego. Jego zespół dąży do „postępu w dziedzinie inteligencji maszyn i tworzy nowe, lepsze technologie komunikacji międzyludzkiej”, a w ostatecznym rozrachunku – do „rozwiązania kwestii AI”.
Warto podkreślić, że dzisiejsza sztuczna inteligencja w niczym nie przypomina tej, do której przyzwyczaiły nas filmy science-fiction. Tak zwana stosowana (wąska) AI polega na zaawansowanym przetwarzaniu informacji i w istocie nie próbuje naśladować sposobu ludzkiego myślenia. Najczęściej narzędzia AI wykorzystują mechanizmy ludzkiego rozumowania jako pewien model w celu ulepszenia usług lub produktów. Sukcesy w dziedzinie budowania silnej (głębokiej) sztucznej inteligencji, tj. maszyny, której zdolności intelektualne są nieodróżnialne od zdolności intelektualnych człowieka, są jednak na tyle skromne, że część ekspertów wątpi, czy jest to w ogóle możliwe.

Tego pesymizmu nie podziela Kai-Fu Lee, autor książki AI Superpowers: China, Silicon Valley, and the New World Order, należący do grona uznanych ekspertów zajmujących się sztuczną inteligencją, skądinąd twórca jednego z pierwszych programów do rozpoznawania mowy. Twierdzi on, że rozwój sztucznej inteligencji przebiega w czterech falach:
- Obecnie powszechnie w użytku jest już internetowa AI. Są to algorytmy profilujące użytkownika, które uczą się z danych masowych związanych z tym, co dana osoba robi w sieci. Ten typ AI odpowiada za poprawne dopasowywanie reklam, produktów (Amazon, Alibaba), proponowanie utworów (YouTube), optymalizowanie poziomu zaangażowania użytkownika poprzez przetwarzanie języka naturalnego i komputerowe przetwarzanie obrazu, etykietowanie użytkowników.
- Coraz powszechniej wykorzystywana jest biznesowa AI. Są to algorytmy, które potrafią łączyć wątki w danych historycznych, których człowiek mógłby ze sobą nie skojarzyć, odkrywać ukryte korelacje między danymi i wydarzeniami, co jest wykorzystywane w bankowości, sektorze ubezpieczeń, a także zaczyna być stosowane w służbie zdrowia czy systemie sądownictwa. Pozwala na optymalizację wydatków, minimalizowanie strat, lepsze dopasowywanie kredytów i polis ubezpieczeniowych.
- W niedługim czasie powstanie perceptywna AI, dzięki której świat wirtualny złączy się ze światem rzeczywistym. Wszechobecne sensory włączone w Internet Rzeczy spowodują, że sztuczna inteligencja zyska zmysły, co przyspieszy jej ewolucję. Ten rodzaj sztucznej inteligencji „wprowadzi wygodę i obfitość świata online do rzeczywistości offline” i stanie się podstawą inteligentnych fabryk, domów, sklepów, inteligentnej konsumpcji itp.
- Zintegrowanie wszystkich poprzednich fal sprawi, że AI będzie w stanie odczuwać i odpowiadać na otaczający ją świat rzeczywisty i wirtualny, przemieszczać się i działać produktywnie, optymalizować własne działania – będzie to autonomiczna AI. Jej przykładem będą np. drony, które za pomocą komputerowego przetwarzania obrazu będą w stanie rozpoznać i wyplenić chwasty na uprawach, lub inne, odporne na ciepło, które samodzielnie ugaszą pożar, a przede wszystkim – humanoidalne roboty wykorzystywane w życiu codziennym i wojsku.
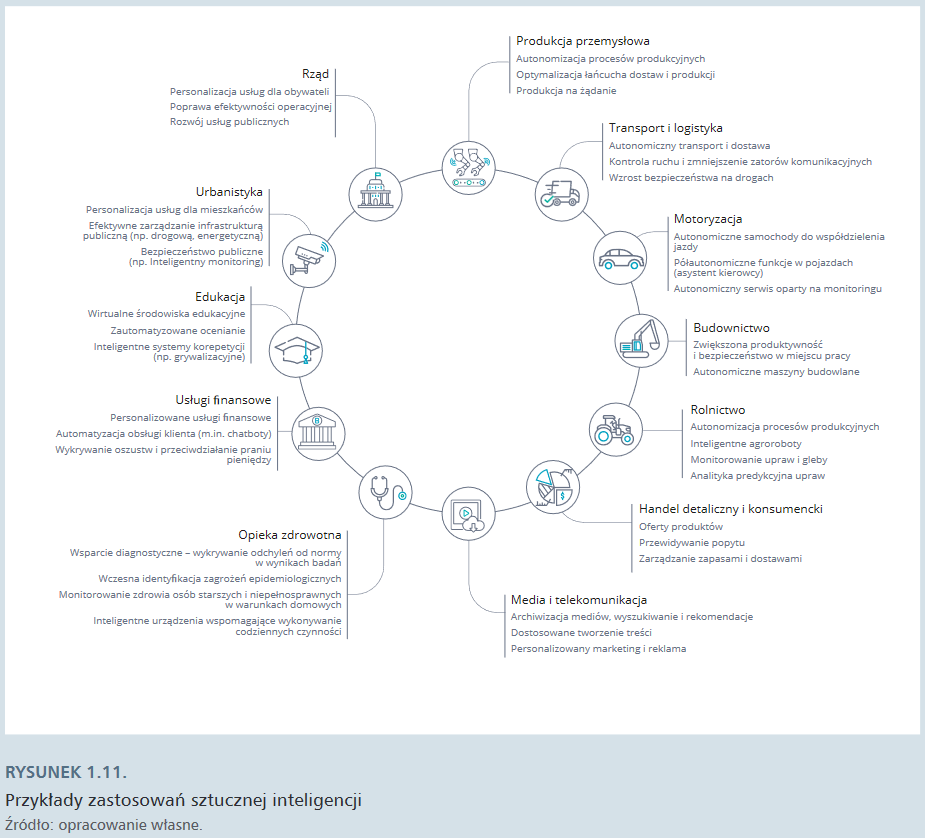
Wysokość rocznych wydatków na technologie IT
Za pośrednictwem usług chmurowych sztuczna inteligencja staje się podręcznym narzędziem wspierającym funkcjonowanie przedsiębiorstw z różnych sektorów.
Jak przewiduje firma doradcza Deloitte, w najbliższych latach nie tylko duże, ale i średnie firmy zintensyfikują wykorzystanie AI. W 2018 r. liczba programów pilotażowych i wdrożeń narzędzi wykorzystujących sztuczną inteligencję w firmach była już dwukrotnie większa niż w 2017 r. Przewiduje się, że wydatki na AI i uczenie maszynowe wzrosną z 12 mld dolarów w 2017 r. do 57,6 mld dolarów w 2021 r.
Robotyzacja
Robot to programowalna maszyna zdolna do autonomicznego wykonywania zadań i manipulacji przedmiotami znajdującymi się w jego otoczeniu. Upowszechnianie się robotów i automatyzacja produkcji były charakterystyczne dla trzeciej rewolucji przemysłowej. W 1962 roku w fabryce General Motors zainstalowano pierwsze „robotyczne ramię”, które mogło wykonywać jeden rodzaj powtarzalnej czynności (w tym wypadku odlewania z metalu). Pod koniec lat 60. naukowcy ze Stanford University zbudowali ramię, które mogło się poruszać w sześciu osiach. W latach 80. nadal jednak były to urządzenia mało mobilne i niepotrafiące wyczuwać otoczenia. Pierwszy robot zdolny postrzegać otoczenie został zbudowany w latach 1966–1972, a jego chybotliwa konstrukcja uzasadniała wybór nazwy – Shakey. Prawdziwie przełomowe znaczenie miał program budowy robotów humanoidalnych podjęty w połowie lat 80. przez japońską firmę Honda. W 2000 r., po 18 latach pracy nad projektem, Honda zaprezentowała niewielkiego robota, przeznaczonego do wypełniania funkcji opiekuńczych, imieniem Asimo, który reagował na polecenia głosowe i gesty. W 2018 r. Honda oficjalnie zakończyła pracę nad robotem, który trafił do muzeum Miraikan w Tokio, jednak rynek robotów humanoidalnych stabilnie rośnie: w 2023 r. jego wartość ma osiągnąć 4 mld dolarów (w 2018 r. – 0,6 mld dolarów).

Obecnie rozwój robotów napędza kilka powiązanych ze sobą technologii, które sprawiają, że są one coraz bardziej autonomiczne, coraz lepiej postrzegają otoczenie, coraz sprawniej i bardziej elastycznie manipulują przedmiotami i coraz lepiej współpracują z ludźmi. Przede wszystkim są to coraz doskonalsze, mniejsze i przy tym tańsze sensory oraz rozwój sztucznej inteligencji, zwłaszcza w zakresie uczenia się maszynowego. Istotne znaczenie mają również wciąż udoskonalane tzw. aktuatory (elementy wykonawcze, wyrobniki), czyli urządzenia wykonawcze, takie jak: silniki, układy hydrauliczne, wzmacniacze czy siłowniki. W 2019 r. na świecie ma pracować 2,6 mln robotów przemysłowych, o milion więcej niż w 2015 r. – większość z nich w sektorze samochodowym, elektrycznym/elektronicznym, metalowym i maszynowym. Dla przemysłu największe znaczenie ma rozwój wielofunkcyjnych robotów, które będą wspomagać siłę roboczą (collaborative robots, cobots) w produkcji przemysłowej, spożywczej, służbie zdrowia i pakowaniu produktów. Podejmowane są również wysiłki tworzenia robotów współdziałających w chmurze (cloud robotics), czyli zdolnych do współdzielenia mocy obliczeniowej i wykonywania skoordynowanych działań.
W październiku 2018 r. Google ogłosiło, że deweloperzy uzyskają dostęp do specjalistycznej platformy Google Cloud Robotics, stanowiącej „otwarty ekosystem rozwiązań w zakresie automatyzacji, opierający się na połączonych w chmurze, współpracujących robotach. Nasze systemy sztucznej inteligencji i uczenia maszynowego pozwolą wyczuć nieprzewidywalny świat fizyczny, umożliwiając powstanie wydajnych robotów w dynamicznym otoczeniu”. Deweloperzy będą mogli wykorzystywać m.in. Google Cartographer, który umożliwia lokalizację w 2D i 3D na zasadzie ciągłego przetwarzania danych z sensorów.
Specyficznym rodzajem robotów są autonomiczne pojazdy. Są to maszyny służące do transportu, poruszające się bez ingerencji człowieka, zdolne wyczuwać środowisko, w którym się znajdują, i ustalać swoją pozycję. Muszą rozpoznawać style jazdy zarówno kierowców i innych aut bezzałogowych, jak i pozostałych uczestników ruchu i dopasowywać decyzje do sytuacji na drodze. Autonomiczny pojazd musi dysponować licznymi sensorami (lidarami, radarami i kamerami), które umożliwiają lokalizację w przestrzeni, osprzętem komputerowym o wysokiej mocy komputacyjnej i niskich potrzebach energetycznych oraz skomputeryzowanym systemem aktuacji (sterowania, hamowania i przyspieszania) reagującym na wyniki algorytmiczne. Istotne znaczenie ma możliwość podłączenia pojazdu do chmury, co wspiera proces uczenia się w oparciu o dane napływające z sensorów, służy do aktualizacji map i danych o ruchu, umożliwia działanie algorytmów służących do wykrywania obiektów, ich klasyfikacji oraz podejmowania decyzji (planowania kursu, trajektorii ruchu, koniecznych manewrów). Nie tak dawno – w 2004 r. – dwaj uznani ekonomiści, Frank Levy i Richard Murnane, twierdzili, że próba pełnej automatyzacji samochodów zakończy się porażką z powodu nadmiaru informacji, jakie maszyna musiałaby przetworzyć w trakcie jazdy. Obecnie nad rozwojem autonomicznych pojazdów pasażerskich pracuje ponad 40 firm, w tym Tesla, Google czy Uber, ale i Amazon, Apple, Audi, BMW. Optymistyczne prognozy mówią o 33 mln autonomicznych pojazdów na drogach w 2040 r. Kilkanaście nagłośnionych przez media wypadków z udziałem autonomicznych pojazdów – np. w marcu 2019 r. z udziałem Tesli, gdy system sterowania nie rozpoznał banera holowanego przez ciężarówkę jako zagrożenia, co zakończyło się zderzeniem i śmiercią kierowcy – stawia wszakże te prognozy pod znakiem zapytania. Niemałe znaczenie dla upowszechniania się tej technologii mają również koszty produkcji i obsługi zrobotyzowanego samochodu. Najbardziej prawdopodobny scenariusz przewiduje szybkie wdrożenie autonomicznych pojazdów na przewidywalnych trasach w niezbyt zmiennym otoczeniu (np. w metrze) oraz w przemyśle i logistyce.

Blockchain
Satoshi Nakamoto to jedna z najbardziej tajemniczych postaci świata nowych technologii. Podobno jest Japończykiem w średnim wieku, ale zapaleńcy podejmujący się analizy składni jego wypowiedzi i wzoru aktywności nocnej uważają, że pod tym pseudonimem może ukrywać się koder Nick Szabo, nieżyjący już miłośnik kryptografii Hal Finney lub cała grupa hakerów. Kimkolwiek jest lub był Satoshi, w październiku 2008 r. na jednej z list dyskusyjnych dla miłośników cyfrowej kryptografii opublikował artykuł zatytułowany Bitcoin: A Peer-to-Peer Electronic Cash System, który stał się początkiem nowego technologicznego szaleństwa. Kilka miesięcy później, 3 stycznia 2009 r., Satoshi wyemitował pierwsze 50 bitcoinów, był to tzw. blok Genesis, składający się z 31 tys. linijek kodu. Pierwsze 10 bitcoinów otrzymał wspomniany Hal Finney.
Bitcoin nie był pierwszą cyfrową walutą. Geniusz Satoshiego polegał jednak na rozwiązaniu kluczowego problemu podwójnego wydatkowania cyfrowej waluty, która jako dobro informacyjne jest z definicji podatna na kopiowanie i wydawanie dowolną liczbę razy. Bitcoin – tak samo jak cyfrowe zdjęcie, plik tekstowy lub nagrany komórką film – to po prostu zasób informacji, zbiór bitów. Te zaś, o czym doskonale wiedzą wszyscy użytkownicy komputerów i smartfonów, można współcześnie kopiować w nieskończoność, bez jakichkolwiek strat jakości, bez czyjejkolwiek zgody lub wiedzy. Satoshi Nakamoto wymyślił jednak taki system obiegu nowej waluty, w którym żaden bitcoin nie może zostać skopiowany, żadnego też nie można wydać dwukrotnie.

Oparta wyłącznie na systemie peer-to-peer wersja pieniądza elektronicznego umożliwiłaby przesyłanie płatności online bezpośrednio między podmiotami, z pominięciem pośrednictwa instytucji finansowej. Częściowo problem ten rozwiązuje podpis cyfrowy, ale korzyści są niewielkie, jeśli nadal tylko zaufana trzecia strona może zapobiec podwójnemu wydatkowaniu środków. Nasza propozycja polega na całościowym rozwiązaniu problemu dzięki wykorzystaniu sieci peer-to-peer. Sieć przypisuje znaczniki czasowe transakcjom, haszując je do ciągle przyrastającego łańcucha dowodów wykonanej pracy [tzw. proof of work – przyp. red.], tworząc zapis, który nie może być zmieniony bez zmiany owych dowodów.
Innymi słowy, Satoshi Nakamoto wpadł na pomysł stworzenia zdecentralizowanego i rozproszonego rejestru transakcji, uniemożliwiającego nadużycia, jakim byłoby wielokrotne wydawanie tych samych monet – cyfrowych egzemplarzy waluty. By jednak system zadziałał, potrzebował wielu użytkowników, którzy zechcą udostępnić zasoby cyfrowe swoich komputerów poprzez zainstalowanie oprogramowania będącego sercem systemu Bitcoina. Zachętą do przyłączania się do sieci była możliwość pozyskania samej waluty. Z początku wystarczyła garstka zapaleńców z laptopami: każdy, kto zechciał ściągnąć na swój komputer określony program, uczestniczył w podtrzymaniu infrastruktury bitcoina. Istotą systemu było zaś kryptograficzne rejestrowanie każdej transakcji, każdego przelewu z jednego portfela do drugiego – to właśnie stanowiło zawartość kolejnych zaszyfrowanych bloków w łańcuchu (stąd nazwa blockchain). Dopisywanie kolejnych bloków, tworzących internetową, rozproszoną księgę rachunkową nowej waluty, choć w pełni zautomatyzowane, zostało jednak wzbogacone o wyjątkowy element. Każdy z użytkowników użyczających swoich komputerów jako węzłów sieci (nodes) mógł „zarobić” kolejnego bitcoina, pod warunkiem, że to właśnie jego maszyna jako pierwsza rozwiązała zagadkę matematyczną i dopisała kolejny blok dokumentujący najnowsze wykonane transakcje do istniejącego już łańcucha. To zautomatyzowane działanie logiczne wykonywane przez algorytmy określa się mianem dowodu wykonanej pracy (proof of work). Za dopisanie kolejnego bloku „właściciel” określonego węzła otrzymuje nagrodę – jednego bitcoina. Ten mechanizm, określany mianem kopania bitcoinów (mining), premiuje oczywiście tych użytkowników, którzy dysponują najsilniejszym sprzętem, co ma swoje logiczne uzasadnienie – ich uczestnictwo w przedsięwzięciu zapewnia stabilność i przekłada się na płynność funkcjonowania całego systemu. Dowód pracy pozwala też zweryfikować autentyczność kolejnych, dopisywanych do łańcucha bloków.
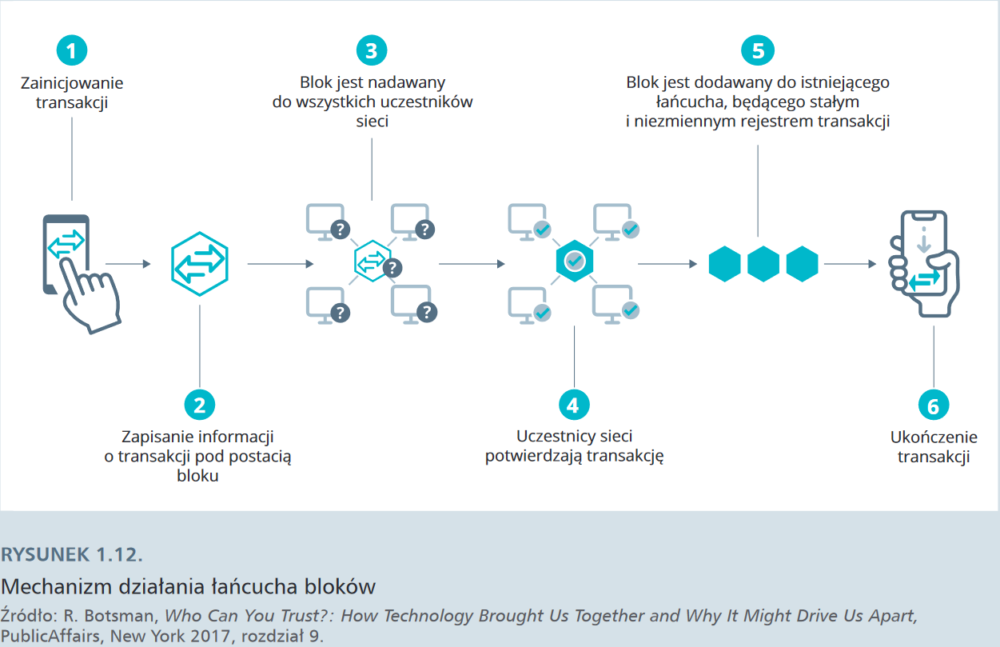
Satoshi wprowadził jednak pewne ograniczenia dla kopaczy: im szybciej przebiegał proces wydobywania, tym zagadki stawały się trudniejsze. Z czasem „kopanie” bitcoinów stało się przedsięwzięciem dla nielicznych. Kopacze muszą mieć potężny sprzęt, wyposażony w specjalne, dedykowane temu procesowi układy scalone oraz dostęp do relatywnie taniej energii elektrycznej. Współczesne zadania logiczne, które rozwiązują komputery kopaczy, są na tyle skomplikowane, że ich rozwikłanie pochłania gigantyczne ilości prądu. W kwietniu 2018 r. szacowano, że rocznie wykorzystanie technologii blockchain pochłania tyle energii elektrycznej, że wystarczyłoby jej na zasilanie całej Austrii przez rok.
Zrozumienie technologii blockchain – w gruncie rzeczy nie tak bardzo skomplikowanej – nastręcza laikom sporo problemów. Nawet supergwiazda świata kryptowalut, Vitalik Buterin, twórca blockchainowej platformy Ethereum i swoisty reformator cyfrowego pieniądza, poproszony o podanie definicji zrozumiałej nawet dla pięciolatka stwierdził, że pięciolatek nie zrozumiałby, czym jest blockchain. Tymczasem technologia blockchaina jest innowacyjnym połączeniem trzech dobrze znanych technologii:
- kryptografii opartej na indywidualnych kluczach dostępu, która zapewnia identyfikację użytkownika w ramach transakcji i w koncepcji Satoshiego zastępuje zaufanie do zewnętrznych pośredników, w tym instytucji finansowych;
- sieci peer-to-peer (sieć komputerów równoważnych), czyli jednego z modeli komunikacji w sieci komputerowej, w której każdy komputer użytkownika pełni dwojaką funkcję klienta i serwera, przykładem sieci P2P są torrenty;
- programu (software), stanowiącego protokół działania blockchainu. Program ten, zapisany na wszystkich komputerach należących do sieci, zawiera opensource’owy algorytm, który wymusza zgodę na wpisywanie do rejestru kolejnych danych. Każdy komputer zapisuje dane niezależnie, ale dokładnie tak samo, jak wszystkie inne komputery w sieci. Po wprowadzeniu nowych zapisów algorytm „pieczętuje” kryptograficznie nowy blok, co gwarantuje, że informacje w nim zawarte nie ulegną zmianie.

Paul Vigna i Michael Casey, autorzy dwóch kanonicznych książek na temat blockchaina: The Age of Cryptocurrency. How Bitcoin and Digital Money Are Challenging the Global Economic Order (2015) oraz The Truth Machine. The Blockchain and the Future of Everything (2018), definiują blockchain jako „cyfrową księgę rozrachunkową działającą w ramach zdecentralizowanej sieci niezależnych komputerów, które ją aktualizują i podtrzymują w taki sposób, który pozwala każdemu udowodnić, że zapis jest kompletny i autentyczny”. Upraszczając, jest to ciągle aktualizująca się rozproszona baza danych. Upraszczając jeszcze bardziej – można sobie wyobrazić blockchain jako zapis transakcji we współdzielonym przez wielu użytkowników arkuszu Google’a. Każdy użytkownik widzi zapisy w rejestrze (jest on publiczny) i może dodawać do niego informacje. Nie może jednak ich samodzielnie zmienić – do zmiany potrzebna jest zgoda 51% wszystkich użytkowników.
Vigna i Cassey rozwijają definicję blockchainu w następujący sposób. Jest to rejestr:
- rozproszony: nie jest zapisany w jednym miejscu, nie istnieje jeden „oryginał”; każdy komputer-węzeł niezależnie aktualizuje rejestr w koordynacji z innymi węzłami;
- wstecznie niemodyfikowalny: praktycznie można do niego tylko dodawać informację. Praktycznie, bo w teorii można zmodyfikować rejestr, o ile zgodzi się na to co najmniej 51% węzłów, tak stało się m.in. w przypadku blockchaina Ethereum. Jednak wymuszona modyfikacja wsteczna wymagałaby olbrzymiej mocy komputacyjnej i wiązałaby się z faktycznym zniszczeniem danego blockchaina;
- wiarygodnie podpisany za pośrednictwem publicznych kluczy szyfrujących. Użytkownicy dysponują dwoma kluczami: jeden jest prywatny (jest czymś w rodzaju PIN), drugi publiczny i powiązany z wartościową informacją (np. liczbą posiadanych bitcoinów), jest czymś w rodzaju adresu mailowego albo numeru konta bankowego). Wykorzystanie prywatnego klucza wysyła informację, że dany użytkownik ma prawo posługiwać się daną informacją, a zatem może ją np. przesłać na publiczny klucz innego użytkownika;
- sekwencyjnie powiązany i zabezpieczony kryptograficznie: poszczególne bloki są powiązane za pośrednictwem niezniszczalnych matematycznych kłódek w potwierdzony łańcuch;
- replikowalny: rejestr jest kopiowany przez wszystkie komputery-węzły uczestniczące w sieci;
- oparty na konsensusie: blockchain wykorzystuje program, który kieruje wszystkich użytkowników w stronę konsensusu pozwalającego harmonizować zapisy w rejestrze. Dlatego też jakiekolwiek zmiany w oprogramowaniu wymagają zgody przynajmniej większości użytkowników, w przeciwnym razie może dojść do rozwidlenia łańcucha bloków i powstania odrębnych wersji rejestru.
Początkowo blockchainy były wykorzystywane głównie do tworzenia kryptowalut. Warto nadmienić, że obecnie jest ich około 1500. Jednak szybko okazało się, że nowa technologia – cechująca się bezpieczeństwem i szybkością transakcji oraz sposobnością do wyeliminowania pośredników – oferuje znacznie większe możliwości. Blockchain może być publiczny i ogólnodostępny, otwarty dla każdego użytkownika (tak jak na przykład bitcoin), albo prywatny i zamknięty, dostępny jedynie dla określonej grupy uczestników pracujących np. w konkretnej gałęzi przemysłu czy łańcuchu dostaw.
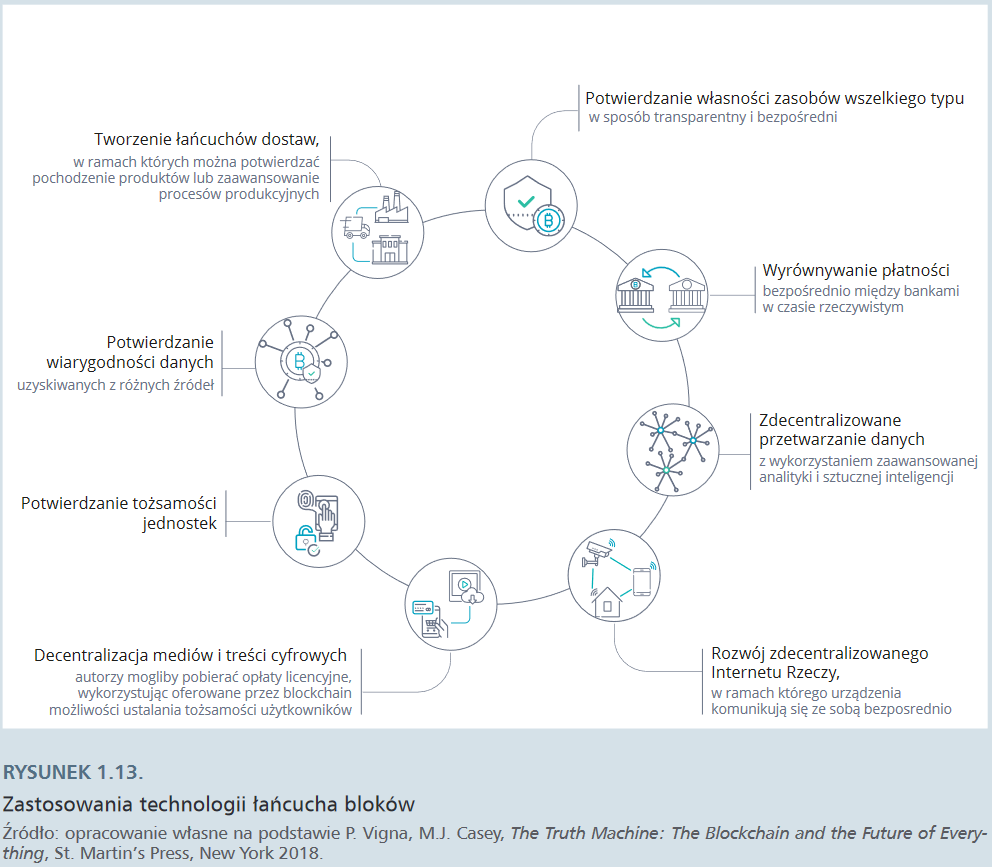
Paradoksalnie może się okazać, że głównym beneficjentem technologii blockchainowej jest system finansowy, który zwolennicy kryptowalut zamierzali otwarcie zwalczać. Blockchain może ułatwić i przyspieszyć ponadgraniczne transfery wartości oraz usprawnić i lepiej zabezpieczyć mechanizmy weryfikacji tożsamości za pośrednictwem blockchainów prywatnych, scentralizowanych i o ograniczonym dostępie. Procesy weryfikacji i autoryzacji relatywnie usystematyzowanych dokumentów lub procedur (takich jak weryfikacja tożsamości klienta czy weryfikacja warunków umów) mogą zostać zautomatyzowe dzięki funkcjonalności „inteligentnych kontraktów” (smart contract). Technologia blockchain jest np. testowana do wykonywania niskokosztowych i szybkich transakcji transgranicznych typu P2P, przede wszystkim przez banki powiązane z firmą Ripple, za pośrednictwem korporacyjnego blockchaina xCurrent. W 2019 r. Facebook wyjawił, że w 2020 r. zacznie funkcjonować system płatniczy (global currency and financial infrastructure) na platformach Messenger i WhatsApp, oparty na kryptowalucie Libra. Według deklaracji firma chciała dotrzeć z usługami finansowymi wykorzystującymi technologię blockchain do 1,7 mld ludzi na świecie, którzy nie mają konta bankowego.
Technologia i zmiana
Jak głosi trzecie z popularnych praw Arthura C. Clarke’a, brytyjskiego pisarza science-fiction, każda odpowiednio zaawansowana technologia jest nieodróżnialna od magii. Poziom zaawansowania obecnej technologii musi być niebotyczny, skoro nawet dziennikarz „Guardiana” zajmujący się nowinkami technologicznymi przyznaje, że internet przypomina mu byt nadprzyrodzony:
Łatwo sobie wyobrazić Thomasa Edisona wynajdującego żarówkę – żarówka to coś namacalnego. Możesz wziąć ją do ręki i przyjrzeć się jej z każdej strony. Internet to coś całkiem innego. Jest wszędzie, ale można dostrzec tylko jego przebłyski. Jest jak Duch Święty: daje się poznać, biorąc w posiadanie piksele na naszym ekranie, by pokazać strony, aplikacje i e-mail, ale jego istota jest wszędzie.
Jeszcze bardziej „magiczne” wrażenie będą sprawiać komputery kwantowe, których działanie opiera się na nieintuicyjnych zasadach fizyki kwantowej. Klasyczny komputer działa na schemacie bitowym z dwiema wartościami: 0 i 1, komputer kwantowy wykorzystuje także stan pośredni – superpozycję. W rezultacie kubit (bit kwantowy) może przyjąć nieskończenie wiele wartości między 0 a 1 i dopiero przy sprawdzeniu przybiera jednoznaczny stan 0 lub 1. Umożliwia to wykonywanie wielu operacji na wszystkich wartościach jednocześnie. Wynik nigdy nie jest pewny, więc konieczne jest wykonywanie serii obliczeń, z których następnie wyciągana jest średnia. Komputery kwantowe wymagają zastosowania specjalnych mikroprocesorów, oprogramowania i osprzętu (są bardzo wrażliwe na wszelkie zmiany warunków zewnętrznych), ale przede wszystkim – złożonych algorytmów opierających się na rozkładzie prawdopodobieństwa. W porównaniu do zwykłego komputera ich wydajność będzie o 18 trylionów razy większa.
Komputery kwantowe przyspieszą przetwarzanie ogromnych zbiorów danych i ułatwią ich analizę, umożliwią nawet łamanie szyfrów i prawdopodobnie również blockchainów. Będą mogły zostać wykorzystane np. do zaawansowanych analiz molekularnych w poszukiwaniu nowych leków. Sęk w tym, że obecnie zwracane przez nie wyniki są nieprecyzyjne. Postęp technologiczny jest jednak niepowstrzymany: w grudniu 2018 r. zespół ekspertów powołany przez amerykańskie National Academies of Sciences, Engineering and Medicine ocenił, że prawdziwie użyteczne komputery kwantowe nie pojawią się wcześniej niż za 10 lat. Jednak w październiku 2019 r. zespół Google ogłosił na łamach czasopisma „Nature” przeprowadzenie udanego eksperymentu z wykorzystaniem komputera kwantowego.
Praca nad kolejnymi wynalazkami i innowacjami w rodzaju komputera kwantowego, nowych baterii czy doskonalszej sztucznej inteligencji trwa nieprzerwanie i skupia na sobie uwagę mediów. Popularny model Gartnera na 2018 r. nie umieścił żadnej nowej technologii na „płaskowyżu produktywności” w przewidywaniu, że potrzeba co najmniej kilku lat, by kolejne technologie weszły do powszechnego użytku. Istotą transformacji cyfrowej jest jednak wdrażanie już istniejących technologii.
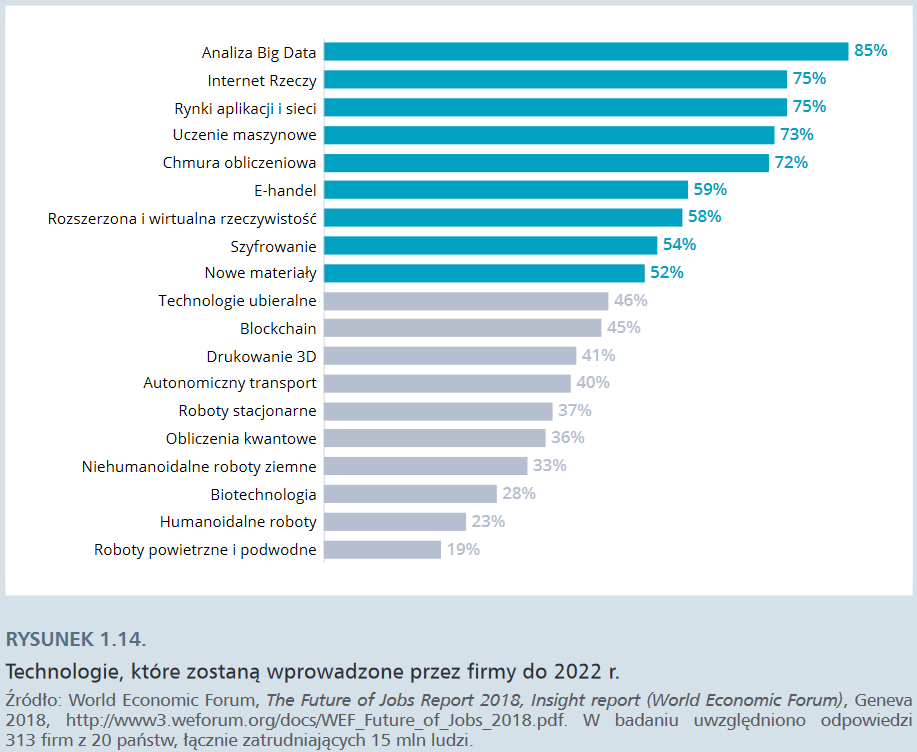
Z 313 firm przebadanych na zlecenie World Economic Forum (z 20 państw świata, łącznie zatrudniających 15 mln ludzi) 85% zamierza inwestować przede wszystkim w analizę dużych zbiorów danych (głównie danych użytkowników własnych produktów i usług). Trzy na cztery firmy zamierzają wdrażać rozwiązania z zakresu IoT, sztucznej inteligencji (uczenia maszynowego), chmury oraz eksplorować możliwości oferowane przez rynki aplikacji i rynki sieciowe. Znacznie mniejszym zainteresowaniem cieszą się rozwiązania związane z robotyką, jednak zastosowanie robotów przekształca funkcjonowanie wielu sektorów gospodarczych.
Technologie, które określiłyśmy jako założycielskie – komputer, internet i smartfon – to technologie, które wspólnie tworzą środowisko generowania danych na niespotykaną wcześniej skalę i umożliwiają ich gromadzenie, przetwarzanie i analizę. Technologie intensyfikujące pozwalają konsumować to bogactwo danych jeszcze bardziej efektywnie: zbierać je, przetwarzać, integrować, analizować i wykorzystywać do rozmaitych celów, od produkcji po konsumpcję, a w ostatecznym rozrachunku – czerpać z pozyskanych w ten sposób informacji wartość ekonomiczną, społeczną lub polityczną. Można więc określić je mianem technologii datafikacji.