
Artykuł jest podrozdziałem pochodzącym z wydanej niedawno książki pt. „Gospodarka cyfrowa. Jak nowe technologie zmieniają świat”. Publikacja powstała w Digital Economy Lab Uniwersytetu Warszawskiego.
Od digityzacji do datafikacji
W latach 80. firmy i instytucje publiczne zaczęły łączyć komputery biurkowe za pośrednictwem lokalnych sieci komputerowych (LAN). Ethernet umożliwiał wymianę danych tylko w postaci cyfrowej, co rodziło różnorodne korzyści, z których najbardziej oczywistymi były szybkość oraz oszczędność (warto jednak zaznaczyć, że dopiero w 1996 r. utrzymywanie archiwów cyfrowych stało się bardziej opłacalne niż papierowych). Przede wszystkim organizacja jako całość zyskiwała dostęp do nowych danych i informacji, które mogła wykorzystywać do poprawy swojej efektywności. Ucyfrowienie procesu upowszechniania informacji radykalnie zwiększyło wolumen wytwarzanych, przechowywanych, przekazywanych i konsumowanych danych.

Coraz więcej analogowych danych i informacji zyskiwało cyfrowy format w procesie digityzacji (w dalszej części wyjaśniamy, co dokładnie oznacza ten termin). Prawdziwy przełom w produkcji danych nastąpił jednak w momencie powstania World Wide Web na początku lat 90. XX w. Bez podłączenia do sieci komputery pozostałyby w istocie kalkulatorami o coraz większej mocy obliczeniowej, lecz o zastosowaniu ograniczonym do uniwersytetów, firm i instytucji publicznych. Internet zachęcił zwykłych ludzi do kupowania i używania komputerów, tabletów i smartfonów. Zarówno organizacje, jak i zwykli użytkownicy zaczęli wytwarzać gigabajty danych. W 2015 r. IBM zakomunikował, że w ciągu dwóch lat (2013–2015) wytworzono 90% wszystkich danych, jakie kiedykolwiek powstały. Ich wolumen przyrasta w tempie wykładniczym, podwajając się co trzy lata. Nic w tym dziwnego – w ciągu jednej minuty wysyłanych jest 188 mln mejli (nie tylko przez ludzi, ale i boty spamujące), powstaje 350 tys. tweetów, wyszukiwarka Google jest używana 3,8 mln razy, a Skype 180 tys. razy.
Kolejnym krokiem milowym stało się upowszechnienie internetu rzeczy: dane zaczęły napływać z dziesiątek urządzeń wyposażonych w sensory, które wyczuwają zmiany w otoczeniu. Zwykły samochód może być wyposażony nawet w 200 czujników, które generują 1 terabajt danych dziennie. Ostrożne szacunki mówią o 26 mld innych urządzeń (mniej ostrożne o nawet 50 mld) i miliardach inteligentnych detektorów tworzących internet rzeczy. W czujniki – np. ruchu – są wyposażone również smartfony, których w 2020 r. będzie 6,1 mld. W efekcie wolumen wszystkich wytworzonych danych zbliży się do niewyobrażalnej liczby 44 zettabajtów (44 razy 1021 bajtów).
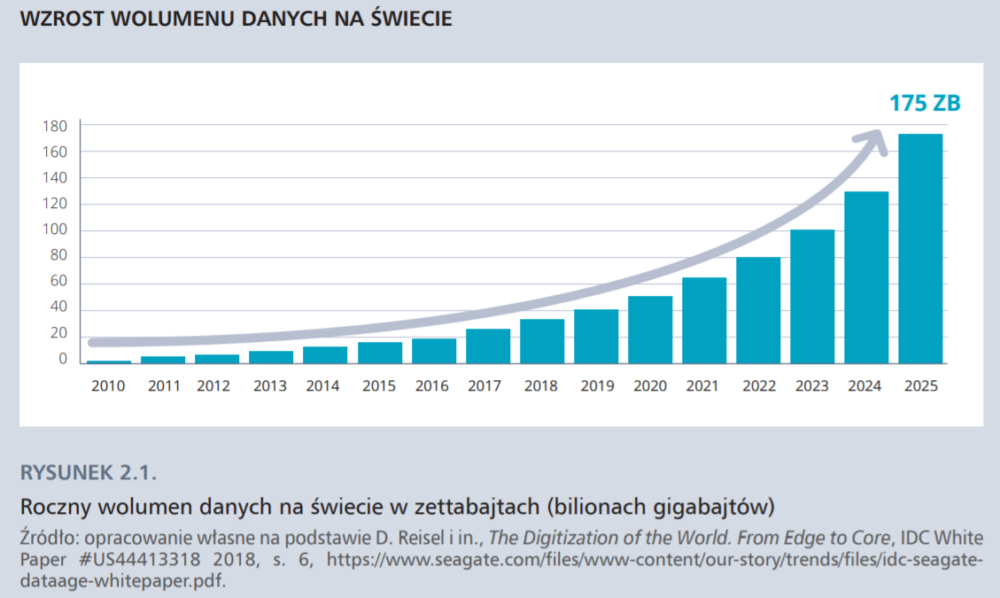
Wszystkie te zmiany można – kierując się sugestią Viktora Mayera-Schönbergera i Kennetha Cukiera (2013) – określić mianem datafikacji (danetyzacji), definiowanej jako narastający proces tworzenia cyfrowych reprezentacji kolejnych obszarów świata rzeczywistego oraz czerpania wartości z pozyskanej w tej sposób informacji. Datafikacja ma doniosłe konsekwencje społeczne i ekonomiczne. Ulega jej życie ludzkie w wielu aspektach: relacje społeczne, zachowania konsumenckie i procesy produkcyjne oraz zaangażowanie polityczne. Datafikacja tworzy również grunt dla nowych modeli biznesowych rozwijanych przez firmy technologiczne i platformy.
Datafikacji ulega na przykład dzieciństwo, o czym alarmuje brytyjski Komisarz ds. Dzieci w raporcie Who knows what about me? (2018). Dane dzieci są zostawiane przez nie same i ich rodziców nie tylko w mediach społecznościowych: są zbierane przez inteligentne zabawki, wirtualnych asystentów, takich jak Siri czy Alexa, oraz inne urządzenia podłączone do internetu i gromadzone za pośrednictwem urządzeń monitorujących noszonych przez dzieci na ciele. Dane, również te biometryczne, zbierają instytucje publiczne – od szkół przez transport publiczny po służbę zdrowia. W rezultacie „dzieci są datafikowane – nie tylko za pośrednictwem mediów społecznościowych, ale w wielu obszarach ich życia”.
Datafikacja wpływa też na sposób funkcjonowania jednostek w społeczeństwie – ludzie mają dostęp do coraz większej ilości danych, które mogą wykorzystywać do podejmowania decyzji życiowych, zawodowych i konsumenckich lepiej dopasowanych do ich preferencji. Jednocześnie datafikacja sprawia, że prywatność staje się ułudą – uczestnictwo w wirtualnym świecie i funkcjonowanie w rzeczywistości przenikniętej cyfrowymi technologiami, korzystanie z cyfrowych produktów i usług pozostawia cyfrowe ślady w postaci danych, które są zbierane i wykorzystywane przez firmy, organizacje i instytucje publiczne.

„Pojęcia digityzacji, digitalizacji/cyfryzacji i transformacji cyfrowej można mylić wyłącznie na własne ryzyko” – napisał w czerwcu 2018 r. w czasopiśmie Forbes James Bloomberg, uznany ekspert od strategii biznesowych. Zdaniem Bloomberga „digityzujemy informacje, digitalizujemy procesy i role wchodzące w zakres operacji biznesowych, a transformujemy cyfrowo firmę i jej strategię”. Problem w tym, że te pojęcia są bliskie znaczeniowo. W polskiej literaturze przedmiotu i publicystyce pojęcia digitalizacji często używa się w znaczeniu digityzacji – przekształcania formatu analogowego na cyfrowy. Na oznaczenie zjawisk, które Bloomberg określa mianem digitalizacji, używa się raczej pojęcia cyfryzacji: pisze się o cyfryzacji procesów, cyfryzacji edukacji, cyfryzacji firm. Zamieszanie pojęciowe pogłębia fakt, że Komisja Europejska konsekwentnie używa pojęcia digityzacji w rozumieniu cyfryzacji. Systematyczny przegląd literatury przedmiotu (206 artykułów naukowych) pokazuje, że termin „transformacja cyfrowa” zyskał popularność dopiero w 2015 r. Definicje transformacji można zaliczyć do trzech kategorii: definicje technologiczne akcentują fakt, że opiera się ona na wykorzystaniu nowych technologii cyfrowych, definicje organizacyjne podkreślają, że transformacja cyfrowa wymaga zmiany procesów organizacyjnych lub utworzenia nowych modeli biznesowych, natomiast społeczne – że jest to zjawisko wpływające na wszystkie obszary ludzkiego życia.
W książce „Gospodarka cyfrowa” stosujemy następujące definicje:
• Digityzacja: przekształcanie analogowego formatu danych na cyfrowy.
• Digitalizacja/cyfryzacja: zastosowanie technologii cyfrowych w poszczególnych procesach gospodarczych, społecznych i politycznych.
• Datafikacja: pozyskiwanie danych poprzez tworzenie cyfrowych reprezentacji świata rzeczywistego w wyniku digityzacji; integracja (przetwarzanie i łączenie zbiorów danych) i analiza danych z wykorzystaniem algorytmów; czerpanie wartości ekonomicznej, społecznej lub politycznej z pozyskanych w ten sposób informacji. Technologie służące gromadzeniu, integracji i analizie danych określamy mianem technologii datafikacji.
• Transformacja cyfrowa: w wąskim rozumieniu – całościowa zmiana funkcjonowania organizacji zachodząca w wyniku wdrożenia technologii cyfrowych; w szerszym rozumieniu – strukturalna zmiana modelu funkcjonowania rynku, konsumentów, przedsiębiorstw i innych organizacji (w tym państwa), pracowników i globalnej gospodarki, następująca dzięki datafikacji.

Nowy czynnik produkcji: dane
W ostatnich latach doszło do symptomatycznego przetasowania na liście korporacji o najwyższej wartości rynkowej tworzonej przez magazyn Fortune 500 (ale też na innych listach rankingowych, jak np. Financial Times Global 500). W 2013 r. w pierwszej piątce firm były dwie firmy technologiczne (Apple i Google), w 2019 r. – cztery (Microsoft, Apple, Amazon i Alphabet, konglomerat i holding utworzony przez Google). To, co decyduje o pozycji i przewadze tych firm, to dane użytkowników – gromadzone i wykorzystywane na masową skalę, np. do analizy preferencji klientów i dostosowywania na tej podstawie oferty marketingowej.
Analitycy MIT Initiative on the Digital Economy oceniają, że 84% wartości rynkowej firm na liście S&P 500 opiera się na zasobach niematerialnych, w tym na wykorzystaniu danych lub software’u. Niespotykany sukces rynkowy firmy takie jak Facebook zawdzięczają również możliwości wykorzystania danych swoich użytkowników m.in. do optymalizacji oferty czy przewidywania zachowań konsumenckich.
Skwantyfikowane interakcje społeczne zostały udostępnione stronom trzecim – innym użytkownikom, firmom, agencjom rządowym czy innym platformom. Cyfrowa transformacja tego, co społeczne, przyczyniła się do powstania przemysłu, który buduje swoją przewagę na wartości danych i metadanych (…). Metadane, jeszcze do niedawna uważane za bezwartościowe produkty uboczne usług dostarczanych przez platformy, stopniowo zostały przekształcone w cenione zasoby, które najwyraźniej mogą być wydobywane, wzbogacane i przekształcane w cenny produkt.
źr. J. van Dijck, Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology, „Surveillance & Society”
Ile warte są dane użytkowników w sieci? Zgrubnie pozwala to oszacować specjalny kalkulator stworzony w 2013 r. i zaktualizowany w 2017 r. przez Financial Times, uwzględniający pięć kategorii: dane demograficzne, rodzinne, dotyczące stanu posiadania oraz aktywności sportowej i konsumenckiej. Dane przeciętnego użytkownika mogą zostać sprzedane za mniej niż pół dolara (od 0,2 do 0,4 dolara), ich wartość będzie różniła się w zależności od ich ilości i specyfiki. Przykładowo, dane osoby tuż po rozwodzie lub planującej ślub czy dzieci, a także dane osoby w gorszym stanie zdrowia, zainteresowanej zakupem nieruchomości i posiadającej łódkę będą wyżej wyceniane, niż dane zdrowych i szczęśliwych małżonków o stabilnym statusie i miejscu zamieszkania. Algorytmy mediów społecznościowych wyszukują informacje o zmianie sytuacji życiowej, która może zaowocować wzmożoną konsumpcją nowych produktów i usług. Pytanie brzmi, czy użytkownicy powinni uzyskiwać wynagrodzenie za wytwarzane dane i czy możliwa jest rzetelna wycena śladu cyfrowego, czyli przede wszystkim danych osobowych, które użytkownicy przekazują usługodawcom internetowym.

W ostatnich latach firmy gromadzące duże zbiory danych odkryły jeszcze jeden sposób czerpania zysków: zaczęły je wykorzystywać w procesie rozwoju usług opartych na sztucznej inteligencji, które następnie są sprzedawane innym podmiotom.
Firmy – i to zarówno korporacje, jak i małe oraz średnie przedsiębiorstwa – nigdy wcześniej nie miały do czynienia z taką ilością danych, które mogą być wykorzystane do podniesienia efektywności produkcji, jej personalizacji, dopasowania oferty marketingowej, ekspansji na nowe rynki albo usprawnienia zarządzania i podejmowania trafnych decyzji w czasie rzeczywistym. Informacje mogą być kupowane, ale są też generowane przez użytkowników produktów i usług danej firmy oraz wytwarzane podczas procesu produkcyjnego w zakładach przemysłowych oplecionych internetem rzeczy. Jak podkreśla Erik Brynjolfsson, dyrektor MIT Initiative on the Digital Economy, coraz większa część zasobów w gospodarce składa się z bitów, a nie z atomów, a zatem dane powinny być traktowane jako zupełnie nowy rodzaj kapitału:
Kiedyś sprzęt komputerowy (computer hardware) traktowano jako zasób podstawowy, o danych nie myślano w ten sposób. Dziś hardware staje się usługą kupowaną w czasie rzeczywistym, a dane – trwałym zasobem.
źr. MIT Technology Review Custom w partnerstwie z Oracle, The Rise of Data Capital, „MIT Technology Review”
Z pewną przesadą można stwierdzić, że dane stały się tym dla współczesnej gospodarki, czym dla gospodarki przemysłowej były węgiel i stal, a w XX w. ropa naftowa: są czynnikiem produkcji, wpływającym na efektywność prowadzenia działalności gospodarczej, ale też determinują rozwój nowych modeli, rozwiązań i relacji gospodarczych. Potraktowane jako kapitał mają interesujące własności:
• Są niezastępowalne (non-fungible) – pojedynczy zbiór danych nie może być zastąpiony innym, bo zawiera zupełnie inną informację. Produkty takie jak baryłka ropy naftowej są doskonale zastępowalne.
• Mają charakter nierywalizacyjny – pojedynczy zbiór danych może być jednocześnie wykorzystywany przez wiele algorytmów czy aplikacji i poddawany analizie, bez utraty jego podstawowej wartości. Tymczasem moneta lub element wyposażenia/infrastruktury mogą być używane tylko przez jednego aktora w danym momencie.
• Ich wartość jest równoznaczna z informacją, jaką zawierają – można ją zatem ocenić dopiero po uzyskaniu informacji (experience good). Uzyskaną informację można jednak łatwo replikować. Tymczasem wartość dobra trwałego można zdobyć, tylko biorąc je w posiadanie – posiadanie informacji na jego temat jest bezużyteczne.

Dane krążące w gospodarce cyfrowej pochodzą z wielu źródeł – również takich, które do niedawna leżały w archiwach publicznych lub na dyskach komputerów, a obecnie są eksplorowane na nowo ze względu na możliwości ich analizy oferowane przez sztuczną inteligencję.
Według amerykańskiej badaczki Shoshany Zuboff obecnie mamy do czynienia z powstawaniem „kapitalizmu nadzoru”, opartego na wykorzystywaniu przez firmy wartości dużych zbiorów danych behawioralnych. To mocna i kontrowersyjna teza.


Niewątpliwie jednak umiejętność czerpania wartości z danych w coraz większym stopniu decyduje o pozycji konkurencyjnej na rynku, zmieniając w rezultacie funkcjonowanie firm i całej gospodarki. Na najbardziej ogólnym poziomie wydajniejsza i szybsza analiza dużych zbiorów danych służy optymalizacji procesów decyzyjnych w organizacjach. W handlu, gdzie dane można pozyskiwać z działów marketingu, sprzedaży, obsługi klienta, ale też z raportów o cenach oraz z mediów społecznościowych, umiejętność ich przetwarzania daje pełniejszy ogląd zachowań kupujących i konkurencji. Dane osobowe, pozyskiwane przez usługodawców w internecie, służą do tworzenia skutecznych kampanii marketingowych, trafiających do właściwych odbiorców. Instytucje finansowe zyskują możliwość szybkiego wykrywania i reagowania na próby oszustw. Sektor publiczny także dostrzega korzyści z analizy – pozwala np. optymalizować działanie transportu publicznego w oparciu o informacje z czytników biletów albo usprawniać służbę zdrowia dzięki raportom rozmaitych sensorów noszonych przez pacjentów. Przede wszystkim jednak dostęp do danych użytkowników, producentów i usługodawców oraz zarządzanie nimi tworzą potencjał platformizacji kolejnych sektorów gospodarki.
Według ekspertów MIT przepis na sukces w gospodarce cyfrowej w oparciu o kapitał danych sprowadza się do trzech zasad:
• Dane biorą się z aktywności. Firma powinna zdigitalizować i zdatafikować kluczowe działania tworzące wartość (value creating activities), zanim to zrobią jej rywale.
• Dane rodzą dane. Algorytmy oparte na danych zbierają dane na temat własnej efektywności, dzięki czemu mogą poprawiać swoje działanie na zasadzie pozytywnego sprzężenia zwrotnego (virtuous circle).
• Platformy zazwyczaj wygrywają. Cyfryzacja i datafikacja sprzyjają platformizacji tradycyjnych przemysłów.
Big data
Duża część obecnie wytwarzanych danych ma specyficzne właściwości: są wysoce zróżnicowane, złożone i zazwyczaj słabo ustrukturyzowane. Dane analogowe – tekstowe czy liczbowe – przed wyryciem na glinianej tabliczce czy zapisaniem w księdze rachunkowej były w jakiś sposób porządkowane, aby kolejny użytkownik wiedział, jak należy je odczytywać. Podobnie wstępnie uporządkowane są zazwyczaj cyfrowe dane gromadzone przez instytucje publiczne, korporacje i organizacje pozarządowe. Natomiast dane generowane przez media społecznościowe, logowania na serwery, zakupy w sieci, systemy geolokacji czy odczyty sensorów są słabo ustrukturyzowane.

W 1997 r. dwaj współpracownicy NASA, Michael Cox i David Ellsworth, zaproponowali, by ten typ danych określać mianem big data (na polski tłumaczy się niekiedy ten termin jako gigadane). Dwa lata później analityk firmy konsultingowej Gartner, Doug Laney, obserwując problemy swoich klientów z danymi pochodzącymi z różnych źródeł, ich strukturą i zróżnicowanymi formatami, stwierdził, że big data cechują się dużym wolumenem (volume), szybkością, z jaką są produkowane (velocity), i różnorodnością (variety). Przez kolejne dwie dekady lista ta wydłużyła się do 10V: oprócz już wymienionych mówi się o wielowymiarowości i niespójności big data (variability), ich stosunkowo niskiej wiarygodności (veracity), jak i trafności i poprawności (validity), podatności na cyberataki (vulnerability), krótkiej przydatności w kontekście opłacalności archiwizacji tak dużych zbiorów danych (volatility), wyzwaniach dotyczących wizualizacji (visualization) oraz ich wartości biznesowej (value). Definicje big data równie często zwracają uwagę na fakt, że do ich zbierania, przetwarzania, analizy i wizualizacji trzeba wykorzystywać niestandardowe metody, niektóre z nich określają big data raczej jako technologie i struktury technologiczne. Cytując zwięzłą definicję zamieszczoną w Wikipedii: „big data to termin określający gromadzenie zbiorów danych tak dużych i złożonych, że trudne staje się ich przetworzenie za pomocą narzędzi do zarządzania bazami danych lub tradycyjnych aplikacji do przetwarzania”. Definicja ta jest zbieżna z definicją OECD, zgodnie z którą:
Termin big data jest na ogół rozumiany jako wykorzystanie potencjału komputacyjnego na dużą skalę oraz technologicznie zaawansowanego oprogramowania do zbierania, przetwarzania i analizowania danych cechujących się dużym wolumenem, szybkością wytwarzania i wartością.
źr. Directorate for Financial and Enterprise Affairs, Competition Committee, Big Data: Bringing Competition Policy to the Digital Era, OECD
„Zanieczyszczenie” dużych zbiorów danych, przejawiające się w ich różnorodności i braku struktury, oraz konieczność sięgania po niestandardowe metody analizy tworzą zapotrzebowanie na nowy rodzaj kompetencji w zakresie data science, która jest czymś więcej niż analizą danych. Przypomina raczej proces rafinacji w informacje użyteczne dla biznesu (i w coraz większym stopniu sektora publicznego). Termin został ukuty w 2008 r. w Dolinie Krzemowej przez dwóch analityków pracujących w LinkedInie i Facebooku, a popularność zyskał w 2012 r. dzięki artykułowi zamieszczonemu w Harvard Business Review, który okrzyknął nowy zawód „najseksowniejszą pracą XXI wieku”. Zadaniem badaczy danych (data scientists) jest „dokonywanie odkryć w zalewie danych” i przekazywanie ich w zrozumiały sposób osobom podejmującym strategiczne decyzje w świecie, w którym „dane nie przestają napływać”.
[Badacze danych] czują się świetnie w cyfrowej rzeczywistości i potrafią nadawać strukturę dużym nieforemnym (formless) grupom danych, by poddać je analizie. Potrafią zidentyfikować bogate źródła danych, łączyć je z innymi, potencjalnie niekompletnymi źródłami i oczyścić powstały w ten sposób zbiór.
źr. T.H. Davenport, D.J. Patil, Data Scientist: The Sexiest Job of the 21st Century, „Harvard Business Review”

Warto podkreślić, że to właśnie czyszczenie i organizowanie danych zajmuje najwięcej czasu: średnio 60%, podczas gdy wyszukiwanie trendów (data mining for patterns) i ulepszanie algorytmów tylko 13%. Kompetencje badaczy danych różnią się od kompetencji analityków danych, którzy zazwyczaj pracują na bardziej ustrukturyzowanych zbiorach. O popycie na tych pierwszych świadczy zresztą wycena rynkowa ich pracy: w 2018 r. w USA badacz danych zarabiał średnio 118 tys. dolarów, analityk danych – 84 tys. dolarów. Ocenia się, że w 2020 r. europejski rynek analizy będzie generował 4% PKB, a jego wartość osiągnie 739 mld euro (w 2016 r. było to 300 mld euro, 2% PKB). W 360 tys. firm zajmujących się obróbką danych może pracować nawet 10,5 mln osób.
Możliwości wykorzystania big data rosną wraz z rozwojem sztucznej inteligencji i opartych na niej nowych narzędziach i technologiach analizy. Zachodzi tu zresztą bezprecedensowe sprzężenie: dopiero pojawienie się ogromnych zbiorów danych umożliwiło aplikację uczenia maszynowego (machine learning) i uczenia głębokiego (deep learning). W rezultacie dane są pozyskiwane, przetwarzane, analizowane i wizualizowane coraz szybciej i efektywniej.
W 2017 r. naukowcy z MIT i Michigan State University wykorzystali zautomatyzowaną, osadzoną w chmurze platformę uczenia maszynowego o nazwie Auto Tune Models (ATM) do rozwiązywania problemów z zakresu analizy danych umieszczonych na platformie crowdsourcingowej (https://www.openml.org/). Na 371 analizowanych przypadków w 30% ATM znalazł lepsze rozwiązanie niż ludzie – i zrobił to sto razy szybciej. Automatyzacja sprawia, że szybsza, trafniejsza i tańsza analiza będzie dostępna dla coraz większej liczby firm, również tych, które nie mogą sobie pozwolić na zatrudnienie zespołu badaczy, a przede wszystkim – równie łatwa jak obecnie używanie arkuszy kalkulacyjnych. Przykładem takiej automatyzacji może być platforma Data Robot, która oczyszcza i reformatuje wprowadzone dane, a następnie przepuszcza przez nie dziesiątki algorytmów. Rozwiązanie trafniejsze niż to zbudowane na standardowych modelach statystycznych „pojawia się jak królik z kapelusza, za jednym kliknięciem, co jest imponujące” – jak ujął to jeden z użytkowników.
Cały ten zasób nie zawsze jest prawidłowo oceniony, wyceniony czy wręcz zauważony. Do rangi swoistego bon-motu urosły już słowa Toma Goodwina, który w 2015 r. stwierdził, że Uber, największa korporacja taksówkarska, nie posiada ani jednego samochodu. Facebook, najpopularniejsze medium na świecie, nie tworzy żadnych treści. Alibaba, najwyżej wyceniony sprzedawca, nie ma niczego na składzie, a Airbnb, największy dostawca usług wynajmu mieszkań, nie posiada żadnych nieruchomości (…) Dzieje się coś ciekawego. Miał oczywiście rację. Firmy takie jak Uber, Alibaba i Airbnb nie posiadają twardych zasobów, natomiast dysponują gigantycznymi zasobami danych i technologią pozwalającą na czerpanie z nich wartości ekonomicznej. Jak napisali naukowcy z MIT: they are light on physical assets but heavy on data assets – są lekkie, gdy zważyć ich fizyczny stan posiadania, lecz ciężkie od danych.

Standardowe wskaźniki ekonomiczne z trudnością wychwytują tę specyfikę nowych modeli biznesowych rozwijanych przez firmy technologiczne i platformy. Audyt finansowy przeprowadzony w 2011 r. dla Facebooka wykazał, że firma ma zasoby warte 6,3 mld dolarów: sprzęt komputerowy, wyposażenie biura i inne rzeczy. Wartość danych będących w jej posiadaniu audytorzy wycenili na zero. Naszym zdaniem ta nieprzystawalność standardowych wskaźników ekonomicznych świadczy o radykalnej zmianie, jaka zachodzi w rzeczywistości gospodarczej i społecznej pod wpływem nowych technologii i zalewu danych. Mamy do czynienia ze zmianą modelu funkcjonowania gospodarki – z wyłanianiem się gospodarki cyfrowej.
Całą książkę pt. „Gospodarka cyfrowa” można znaleźć w naszym dziale Biblioteka 4.0, którą autorki postanowiły opublikować w internecie za darmo. DELab UW sprzedaje opracowanie tylko w wersji audiobooka.




