
Czy autonomiczny samochód będzie czekał na połączenie z serwerownią, by skorygować trasę po nagłym manewrze wymuszonym silnymi opadami śniegu? A może inżynierowie w elektrowni będą czekali do następnego dnia, gdy nagrania pracy turbiny zostaną przeanalizowane przez algorytmy uczenia maszynowego, które wykryją niepokojące odgłosy zwiastujące awarię? Czy wreszcie – dane pochodzące z wartej wiele milionów dolarów wywrotki pracującej gdzieś wysoko w Andach w kopalni miedzi będą leżały niewykorzystane i oczekiwały na przylot wykwalifikowanego serwisanta, który prześle je do analizy u producenta opon?
W wymienionych tutaj oraz wielu innych przypadkach, w których wartością krytyczną jest czas, coraz częściej mówimy o przetwarzaniu na brzegu, czyli o edge computingu. Jest ono nierozerwalnie związane z rozwojem internetu rzeczy, jego uzupełnieniem w przypadkach, gdy relacja czasu do wartości, dostępne pasmo czy opóźnienie mają kluczowe znaczenie. To szybko rosnąca nowa strategia budowy infrastruktury IT, szczególnie istotna dla gałęzi gospodarki dysponujących licznymi, rozproszonymi urządzeniami i aplikacjami – więc dla przemysłu, energetyki, usług komunalnych oraz transportu.
Edge computing, edge infrastructure, intelligent edge…
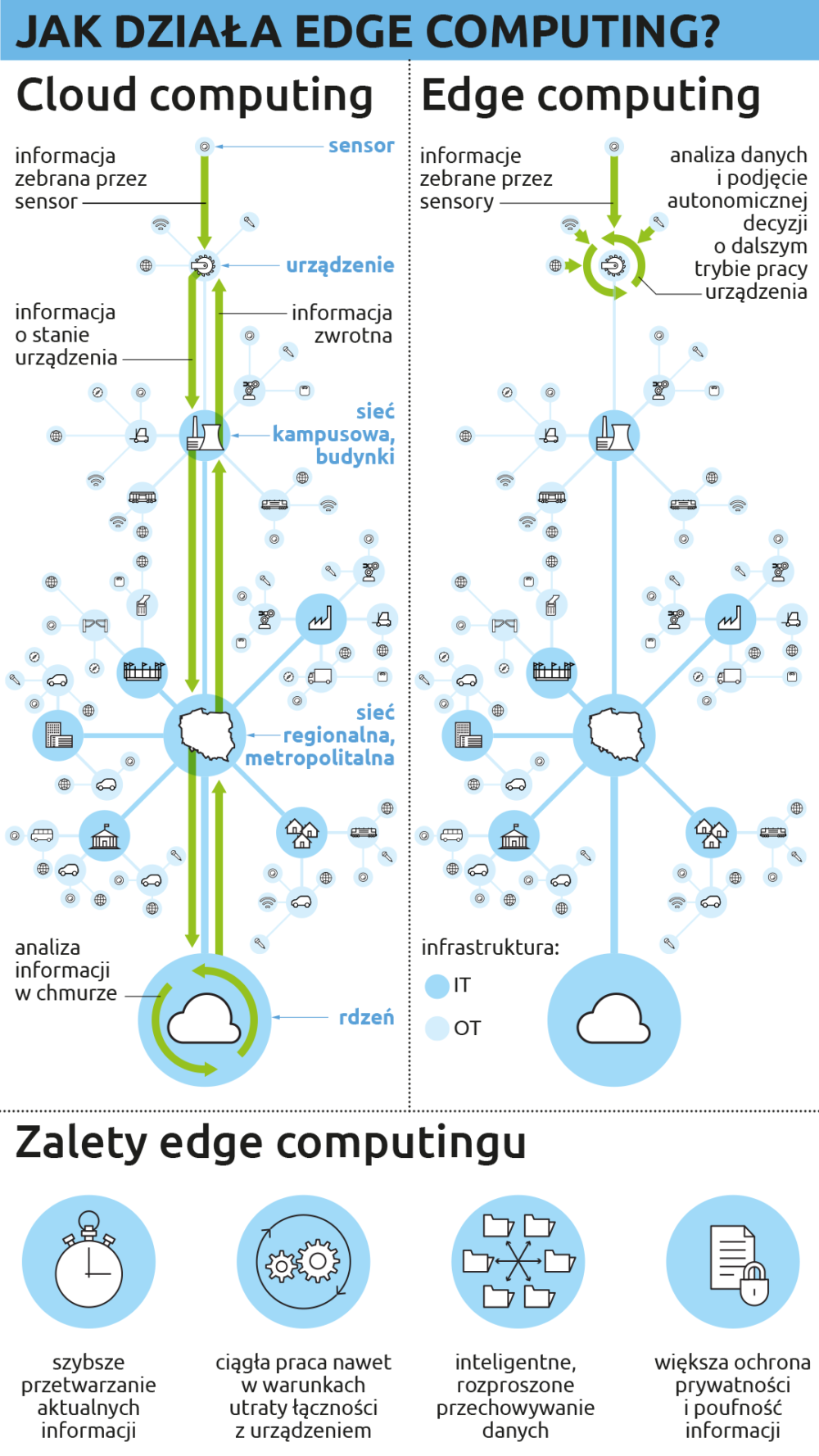
W IDC definiujemy edge computing jako proces przetwarzania danych związanych z IoT, który ma miejsce poza rdzeniem infrastruktury IT, czyli serwerownią, jednak nie będące też podstawowym przetwarzaniem danych właściwym dla czujników czy maszyn. Istotnym elementem jest infrastruktura brzegowa (edge infrastructure), czyli wszystkie urządzenia przetwarzające, przechowujące i przenoszące dane między podłączonymi sensorami, kolektorami a infrastrukturą w rdzeniu. Może to być zarówno sprzęt przedsiębiorstwa, jak i usługa chmurowa.
Komputery procesujące dane na brzegu są z reguły wyposażone w wyspecjalizowane aplikacje i wbudowane systemy operacyjne, sam proces ich przetwarzania jest częściowo albo w pełni niezależny od tego w centralnej serwerowni. W okresie poprzedzającym rozwój IoT dane zbierane z różnych mierników i czujników były przetwarzane albo w systemach IT w serwerowniach, albo w systemach OT (operational technologies), czyli w komputerach zlokalizowanych w fabrykach, inteligentnych budynkach lub w środkach transportu. IoT burzy mur rozdzielający te dwie rzeczywistości, tworząc jednolity świat danych nazywany inteligentnym brzegiem (intelligent edge).
3 rodzaje edge infrastructure
Ze względu na charakter lokalizacji można wyróżnić następujące typy infrastruktury brzegowej:
1. Regionalna (metro) – to tak naprawdę lokalne serwerownie, często zarządzane przez dostawców usług w rodzaju kolokacji, wyposażone w standardowy sprzęt IT. Z reguły są zlokalizowane blisko punktów zbierania danych, służąc ich agregacji i analizie.
2. Kampusowa – charakterystyczne dla sieci kampusowych, przykładowo: infrastruktura IT stadionów. Często takie miejsca mają również własną sieć radiową (radio access network), dlatego oprócz typowej infrastruktury są wyposażone w urządzenia telekomunikacyjne, jak kontrolery, switche i rutery.
3. Budynkowa – infrastruktura położona poza serwerownią, ale jak najbliżej miejsca zbierania danych (fabryka, magazyn, statek, pociąg). Często dane są przesyłane bezpośrednio z monitorowanego sprzętu (urządzenia mobilne, maszyna, inteligentny licznik) albo za pośrednictwem jednego gatewaya zbierającego dane. Mogą to być mniejsze rozwiązania projektowane specjalnie do podobnych zadań dysponujące odporną na uderzenia i warunki atmosferyczne obudową, własnym zasilaniem oraz zdolne do pracy przy ograniczonym paśmie albo nawet bez łączności bezprzewodowej.
Przewagi edge computingu
Głównym powodem rozwijania infrastruktury brzegowej jest przetwarzanie i transmitowanie danych, ale coraz częściej również analiza oraz autonomiczne przenoszenie procesów podejmowania decyzji w oparciu o dane i algorytmy uczenia maszynowego.
Najważniejsze zalety tego typu rozwiązań:
1. Lepszy wskaźnik czasu do wartości danych – opóźnienie jest redukowane przez ograniczenie potrzeby transmisji danych do centralnej serwerowni, dzięki czemu decyzje mogą być podejmowane szybciej na podstawie lepszych, bardziej szczegółowych danych. Ma to znaczenie zwłaszcza dla instalacji ratunkowych, militarnych oraz dla autonomicznych pojazdów.
2. Przetwarzanie w warunkach słabej łączności – lepsze wykorzystanie danych zbieranych na wsiach, w rejonach ze słabą albo zawodną łącznością. W tych przypadkach łączność z centralną serwerownią może być ograniczona albo powolna.
3. Inteligentne rozproszone systemy przechowywania danych – duże zbiory danych IoT mogą być analizowane bez potrzeby ich przesyłania do serwerowni, co przyśpiesza proces podejmowania decyzji, jak również pozwala ograniczyć koszty (np. filmy generowane przez kamery CCTV). Najprawdopodobniej nawet rozpowszechnienie się sieci 5G nie spowoduje, że dane gromadzone przez autonomiczne samochody, drony albo samoloty będą przesyłane do serwerowni.
4. Lepsza prywatność i zarządzanie danymi – obecnie dane zbierane przez instalacje IoT są raczej narażone na kradzież czy zafałszowanie. Ale w dłuższym okresie świadomość ich istnienia wzrośnie i tego typu zagrożenia będą dotyczyły raczej etapu transmisji danych do serwerowni za pomocą publicznych sieci. W tym scenariuszu edge zapewni wyższe bezpieczeństwo danych.

Trzeba zmienić strategię IT
Przetwarzanie na brzegu decentralizuje analizę danych w kierunku krańca sieci, wykorzystując jednocześnie algorytmy zaszyte w węzłach będących blisko miejsca ich zbierania i gromadzenia. Wymienione zalety tego modelu będą miały znaczący wpływ na nowe strategie budowy środowisk IT, szczególnie w niektórych branżach. Nowa generacja rozwiązań wymusi szereg zmian w strategiach technologicznych wielu organizacji:
1. Aplikacje, middleware i bazy danych zainstalowane na brzegu będą musiały ewoluować, aby dostosować się do nowych modeli zarządzania IT, co poskutkuje nowymi kosztami.
2. Architekturę i zarządzanie siecią trzeba będzie dostosować do zmieniających się przepisów, aby decyzje podejmowano we właściwym miejscu i czasie. Nowe podejście jest także niezbędne do zapobiegania sytuacjom, w których sieć zatyka się przez nadmierny ruch na brzegu sieci.
3. Zmieni się rola usług w chmurze, które obecnie są zazwyczaj scentralizowane i mają charakter liniowy. Wyzwaniem dla wielu organizacji stanie się model, w którym analiza wstępna nastąpi na brzegu, a następnie infrastruktura podstawowej serwerowni prześle pakiety danych do chmury. Dostawcy chmury, którzy nie zaproponują bardziej zdecentralizowanego podejścia mogą stracić klientów.
4. Firmy konsultingowe, wdrożeniowe, świadczące wsparcie i integrację będą musiały rozszerzyć swoje kompetencje o nowe umiejętności dotyczące rozwoju infrastruktury IT w modelu edge computingu.

Do czego przyda się obliczanie brzegowe?
Już pobieżna analiza rynku IoT pozwala zbudować długą listę przykładów sytuacji, w których przetwarzanie brzegowe daje istotne korzyści:
1. Ekosystemy posiadające dużą liczbę urządzeń końcowych rozproszonych na większym obszarze, takie jak inteligentna sieć przesyłowa, czy systemy monitoringu środowiska. Infrastruktura edge’owa może analizować zebrane dane, przesyłając do centralnych systemów tylko wartościowe informacje.
2. Kontekstowy marketing wewnątrz sklepów – przetwarzanie danych na miejscu i zwracanie kontekstowych informacji do smartfonów klientów w sklepie to modelowy przykład wykorzystania technologii w strategiach sprzedaży wielokanałowych.
3. Predictive Maintenance urządzeń w szczególności na terenach odległych (kopalnie, elektrownie wodne) pozwoli na szybkie wykrywanie potencjalnych zagrożeń dla ciągłości produkcji, redukując potrzebę przeprowadzania kosztownych planowanych przeglądów.
4. Nadzór wideo oraz systemy wykorzystywane przez służby odpowiedzialne za bezpieczeństwo narodowe dzięki przetwarzaniu na brzegu będą mogły znacząco przyśpieszyć reakcję działania, eliminując czasochłonne i kosztowne transmisje pakietów informacji do centrów przetwarzania danych.
Wszystkie wymienione wyżej rozwiązania wykorzystujące przetwarzanie na brzegu mają kilka cech wspólnych. To: liczne urządzenia końcowe, często rozproszone na dużym obszarze, korzyści z lokalnego przetwarzania i analizy danych pozwalające uniknąć problemów z łącznością o odpowiednich parametrach czy szybki dostęp do informacji oraz rekomendacji przygotowywanych przez systemy AI.
Branża produkcyjna powinna już uwzględniać w budżetach edge computing?
Przede wszystkim warto zapoznać się z prawdziwymi przykładami wdrożeń takich instalacji i najlepiej, żeby były one jak najbardziej zbliżone do specyfiki naszej organizacji. Analizując projekty, maksymalnie należy skupić się na oszczędnościach, które mogą wynikać z lepszej lub szybszej analizy danych na brzegu sieci.

Warto także zastanowić się, czy rzeczywiście specjalne rozwiązania edge computingowe są odpowiednią opcją, czy zapewniają właściwą przepustowość, typ komunikacji sieciowej, zasilania oraz analizę danych. Może się bowiem okazać, że w zupełności wystarczy „sprzęt z półki”. Jeśli jednak myślimy poważnie o analizie danych na brzegu, istotne może być uwzględnienie, czy oraz w jaki sposób dane będą analizowane w chmurze, aby później nie okazało się, że zakupiony system operacyjny czy middleware nie współpracuje ze środowiskiem wybranej chmury.
Następnym krokiem w planowaniu powinno być uwzględnienie przetwarzania na brzegu w całej strategii technologicznego rozwoju, żeby uniknąć sytuacji budowania nowych wysp IT, które będą oddzielone od innych środowisk informatycznych. Taka pokusa istnieje w szczególności, jeśli będziemy traktowali wszystko, co dzieje się na brzegu, jako domenę OT, a nie IT.
Obecnie technologia edge jest w początkowej fazie rozwoju i dla wielu producentów infrastruktury stanowi doskonałą obietnicę nowych zamówień w branżach, która dopiero zaczynają poddawać się transformacji cyfrowej. Nie zawsze idzie za tym pełne zrozumienie wyzwań związanych z procesem oraz wiedza branżowa. Dlatego jest istotne, aby zamawiający dobrze zapoznał się z ofertą, planami jej rozwoju i całym ekosystemem sprzedaży. Pytanie, które w tym miejscu naturalnie powinno się pojawić, brzmi: czy producent danego rozwiązania tworzy cały ekosystem z technologią IoT i analityką danych?
Przetwarzanie na brzegu jest istotnym dodatkiem do istniejącej infrastruktury IT, nie może być natomiast traktowane jako oferta jej wymiany pod atrakcyjnym hasłem marketingowym. Powinno być więc strategiczną decyzją, do procesu podjęcia której warto zaprosić wypróbowanego doradcę i usługodawcę, mających już doświadczenie w takich projektach.
Ponad 1/3 firm przetwarza dziś dane na brzegu
Badania firm analitycznych pokazują, że użytkownicy IoT różnią się w podejściu do przetwarzania i analizy danych. Według raportu IDC „EMEA IoT Survey 2017” (Europa, Środkowy Wschód i Afryka), 37% respondentów przetwarza dane pochodzące z internetu rzeczy na scentralizowanych platformach, a 36% na brzegu – w urządzeniach lub sensorach. Respondenci pytani o swoje plany sygnalizują: 37% zamierza procesować dane w ramach edge computingu, 29% chce je przechowywać w chmurze, a 27% zamierza stosować chmurowe platformy streamingowe.
Obliczanie brzegowe, podobnie jak IIoT, ciągle jest stosunkowo młodym trendem zaliczanym do Przemysłu 4.0. Nie ma żadnych wątpliwości, że jest to element bardzo istotny, skoro dla P4.0 właśnie dane, zbierane i przetwarzane podczas całego procesu produkcji, są kluczowe. W konsekwencji obliczanie na brzegu nie powinno być traktowane jako alternatywna część strategii przedsiębiorstwa, która może, ale nie musi zaistnieć. Z całą pewnością edge computing jest jednym z najważniejszych składników czwartej rewolucji przemysłowej.




